如果你曾经或多或少地写过JS,那么你很可能对它的语法感到十分熟悉。当然有一些奇怪之处,但是总体来讲这是一种与其他语言有很多相似之处的,相当合理而且直接的语法。
然而,ES6增加了好几种需要费些功夫才能习惯的新语法形式。在这一章中,我们将遍历它们来看看葫芦里到底卖的什么药。
提示: 在写作本书时,这本书中所讨论的特性中的一些已经被各种浏览器(Firefox,Chrome,等等)实现了,但是有一些仅仅被实现了一部分,而另一些根本就没实现。如果直接尝试这些例子,你的体验可能会夹杂着三种情况。如果是这样,就使用转译器尝试吧,这些特性中的大多数都被那些工具涵盖了。ES6Fiddle是一个了不起的尝试ES6的游乐场,简单易用,它是一个Babel转译器的在线REPL。
块儿作用域声明
你可能知道在JavaScript中变量作用域的基本单位总是function。如果你需要创建一个作用域的块儿,除了普通的函数声明以外最流行的方法就是使用立即被调用的函数表达式(IIFE)。例如:
var a = 2;(function IIFE(){var a = 3;console.log( a ); // 3})();console.log( a ); // 2
let声明
但是,现在我们可以创建绑定到任意的块儿上的声明了,它(勿庸置疑地)称为 块儿作用域。这意味着一对{ .. }就是我们用来创建一个作用域所需要的全部。var总是声明附着在外围函数(或者全局,如果在顶层的话)上的变量,取而代之的是,使用let:
var a = 2;{let a = 3;console.log( a ); // 3}console.log( a ); // 2
迄今为止,在JS中使用独立的{ .. }块儿不是很常见,也不是惯用模式,但它总是合法的。而且那些来自拥有 块儿作用域 的语言的开发者将很容易认出这种模式。
我相信使用一个专门的{ .. }块儿是创建块儿作用域变量的最佳方法。但是,你应该总是将let声明放在块儿的最顶端。如果你有多于一个的声明,我推荐只使用一个let。
从文体上说,我甚至喜欢将let放在与开放的{的同一行中,以便更清楚地表示这个块儿的目的仅仅是为了这些变量声明作用域。
{ let a = 2, b, c;// ..}
它现在看起来很奇怪,而且不大可能与其他大多数ES6文献中推荐的文法吻合。但我的疯狂是有原因的。
这是另一种实验性的(不是标准化的)let声明形式,称为let块儿,看起来就像这样:
let (a = 2, b, c) {// ..}
我称这种形式为 明确的 块儿作用域,而与var相似的let声明形式更像是 隐含的,因为它在某种意义上劫持了它所处的{ .. }。一般来说开发者们认为 明确的 机制要比 隐含的 机制更好一些,我主张这种情况就是这样的情况之一。
如果你比较前面两个形式的代码段,它们非常相似,而且我个人认为两种形式都有资格在文体上称为 明确的 块儿作用域。不幸的是,两者中最 明确的 let (..) { .. }形式没有被ES6所采用。它可能会在后ES6时代被重新提起,但我想目前为止前者是我们的最佳选择。
为了增强对let ..声明的 隐含 性质的理解,考虑一下这些用法:
let a = 2;if (a > 1) {let b = a * 3;console.log( b ); // 6for (let i = a; i <= b; i++) {let j = i + 10;console.log( j );}// 12 13 14 15 16let c = a + b;console.log( c ); // 8}
不要回头去看这个代码段,小测验:哪些变量仅存在于if语句内部?哪些变量仅存在于for循环内部?
答案:if语句包含块儿作用域变量b和c,而for循环包含块儿作用域变量i和j。
你有任何迟疑吗?i没有被加入外围的if语句的作用域让你惊讶吗?思维上的停顿和疑问 —— 我称之为“思维税” —— 不仅源自于let机制对我们来说是新东西,还因为它是 隐含的。
还有一个灾难是let c = ..声明出现在作用域中太过靠下的地方。传统的被var声明的变量,无论它们出现在何处,都会被附着在整个外围的函数作用域中;与此不同的是,let声明附着在块儿作用域,而且在它们出现在块儿中之前是不会被初始化的。
在一个let ..声明/初始化之前访问一个用let声明的变量会导致一个错误,而对于var声明来说这个顺序无关紧要(除了文体上的区别)。
考虑如下代码:
{console.log( a ); // undefinedconsole.log( b ); // ReferenceError!var a;let b;}
警告: 这个由于过早访问被let声明的引用而引起的ReferenceError在技术上称为一个 临时死区(Temporal Dead Zone —— TDZ) 错误 —— 你在访问一个已经被声明但还没被初始化的变量。这将不是我们唯一能够见到TDZ错误的地方 —— 在ES6中它们会在几种地方意外地发生。另外,注意“初始化”并不要求在你的代码中明确地赋一个值,比如let b;是完全合法的。一个在声明时没有被赋值的变量被认为已经被赋予了undefined值,所以let b;和let b = undefined;是一样的。无论是否明确赋值,在let b语句运行之前你都不能访问b。
最后一个坑:对于TDZ变量和未声明的(或声明的!)变量,typeof的行为是不同的。例如:
{// `a` 没有被声明if (typeof a === "undefined") {console.log( "cool" );}// `b` 被声明了,但位于它的TDZ中if (typeof b === "undefined") { // ReferenceError!// ..}// ..let b;}
a没有被声明,所以typeof是检查它是否存在的唯一安全的方法。但是typeof b抛出了TDZ错误,因为在代码下面很远的地方偶然出现了一个let b声明。噢。
现在你应当清楚为什么我坚持认为所有的let声明都应该位于它们作用域的顶部了。这完全避免了偶然过早访问的错误。当你观察一个块儿,或任何块儿的开始部分时,它还更 明确 地指出这个块儿中含有什么变量。
你的块儿(if语句,while循环,等等)不一定要与作用域行为共享它们原有的行为。
这种明确性要由你负责,由你用毅力来维护,它将为你省去许多重构时的头疼和后续的麻烦。
注意: 更多关于let和块儿作用域的信息,参见本系列的 作用域与闭包 的第三章。
let + for
我偏好 明确 形式的let声明块儿,但对此的唯一例外是出现在for循环头部的let。这里的原因看起来很微妙,但我相信它是更重要的ES6特性中的一个。
考虑如下代码:
var funcs = [];for (let i = 0; i < 5; i++) {funcs.push( function(){console.log( i );} );}funcs[3](); // 3
在for头部中的let i不仅是为for循环本身声明了一个i,而且它为循环的每一次迭代都重新声明了一个新的i。这意味着在循环迭代内部创建的闭包都分别引用着那些在每次迭代中创建的变量,正如你期望的那样。
如果你尝试在这段相同代码的for循环头部使用var i,那么你会得到5而不是3,因为在被引用的外部作用域中只有一个i,而不是为每次迭代的函数都有一个i被引用。
你也可以稍稍繁冗地实现相同的东西:
var funcs = [];for (var i = 0; i < 5; i++) {let j = i;funcs.push( function(){console.log( j );} );}funcs[3](); // 3
在这里,我们强制地为每次迭代都创建一个新的j,然后闭包以相同的方式工作。我喜欢前一种形式;那种额外的特殊能力正是我支持for(let .. ) ..形式的原因。可能有人会争论说它有点儿 隐晦,但是对我的口味来说,它足够 明确 了,也足够有用。
let在for..in和for..of(参见“for..of循环”)循环中也以形同的方式工作。
const声明
还有另一种需要考虑的块儿作用域声明:const,它创建 常量。
到底什么是一个常量?它是一个在初始值被设定后就成为只读的变量。考虑如下代码:
{const a = 2;console.log( a ); // 2a = 3; // TypeError!}
变量持有的值一旦在声明时被设定就不允许你改变了。一个const声明必须拥有一个明确的初始化。如果想要一个持有undefined值的 常量,你必须声明const a = undefined来得到它。
常量不是一个作用于值本身的制约,而是作用于变量对这个值的赋值。换句话说,值不会因为const而冻结或不可变,只是它的赋值被冻结了。如果这个值是一个复杂值,比如对象或数组,那么这个值的内容仍然是可以被修改的:
{const a = [1,2,3];a.push( 4 );console.log( a ); // [1,2,3,4]a = 42; // TypeError!}
变量a实际上没有持有一个恒定的数组;而是持有一个指向数组的恒定的引用。数组本身可以自由变化。
警告: 将一个对象或数组作为常量赋值意味着这个值在常量的词法作用域消失以前是不能够被垃圾回收的,因为指向这个值的引用是永远不能解除的。这可能是你期望的,但如果不是你就要小心!
实质上,const声明强制实行了我们许多年来在代码中用文体来表明的东西:我们声明一个名称全由大写字母组成的变量并赋予它某些字面值,我们小心照看它以使它永不改变。var赋值没有强制性,但是现在const赋值上有了,它可以帮你发现不经意的改变。
const可以 被用于for,for..in,和for..of循环(参见“for..of循环”)的变量声明。然而,如果有任何重新赋值的企图,一个错误就会被抛出,例如在for循环中常见的i++子句。
const用还是不用
有些流传的猜测认为在特定的场景下,与let或var相比一个const可能会被JS引擎进行更多的优化。理论上,引擎可以更容易地知道变量的值/类型将永远不会改变,所以它可以免除一些可能的追踪工作。
无论const在这方面是否真的有帮助,还是这仅仅是我们的幻想和直觉,你要做的更重要的决定是你是否打算使用常量的行为。记住:源代码扮演的一个最重要的角色是为了明确地交流你的意图是什么,不仅是与你自己,而且还是与未来的你和其他的代码协作者。
一些开发者喜欢在一开始将每个变量都声明为一个const,然后当它的值在代码中有必要发生变化的时候将声明放松至一个let。这是一个有趣的角度,但是不清楚这是否真正能够改善代码的可读性或可推理性。
就像许多人认为的那样,它不是一种真正的 保护,因为任何后来的想要改变一个const值的开发者都可以盲目地将声明从const改为let。它至多是防止意外的改变。但是同样地,除了我们的直觉和感觉以外,似乎没有客观和明确的标准可以衡量什么构成了“意外”或预防措施。这与类型强制上的思维模式类似。
我的建议:为了避免潜在的令人糊涂的代码,仅将const用于那些你有意地并且明显地标识为不会改变的变量。换言之,不要为了代码行为而 依靠 const,而是在为了意图可以被清楚地表明时,将它作为一个表明意图的工具。
块儿作用域的函数
从ES6开始,发生在块儿内部的函数声明现在被明确规定属于那个块儿的作用域。在ES6之前,语言规范没有要求这一点,但是许多实现不管怎样都是这么做的。所以现在语言规范和现实吻合了。
考虑如下代码:
{foo(); // 好用!function foo() {// ..}}foo(); // ReferenceError
函数foo()是在{ .. }块儿内部被声明的,由于ES6的原因它是属于那里的块儿作用域的。所以在那个块儿的外部是不可用的。但是还要注意它在块儿里面被“提升”了,这与早先提到的遭受TDZ错误陷阱的let声明是相反的。
如果你以前曾经写过这样的代码,并依赖于老旧的非块儿作用域行为的话,那么函数声明的块儿作用域可能是一个问题:
if (something) {function foo() {console.log( "1" );}}else {function foo() {console.log( "2" );}}foo(); // ??
在前ES6环境下,无论something的值是什么foo()都将会打印"2",因为两个函数声明被提升到了块儿的顶端,而且总是第二个有效。
在ES6中,最后一行将抛出一个ReferenceError。
扩散/剩余
ES6引入了一个新的...操作符,根据你在何处以及如何使用它,它一般被称作 扩散(spread) 或 剩余(rest) 操作符。让我们看一看:
function foo(x,y,z) {console.log( x, y, z );}foo( ...[1,2,3] ); // 1 2 3
当...在一个数组(实际上,是我们将在第三章中讲解的任何的 可迭代 对象)前面被使用时,它就将数组“扩散”为它的个别的值。
通常你将会在前面所展示的那样的代码段中看到这种用法,它将一个数组扩散为函数调用的一组参数。在这种用法中,...扮演了apply(..)方法的简约语法替代品,在前ES6中我们经常这样使用apply(..):
foo.apply( null, [1,2,3] ); // 1 2 3
但...也可以在其他上下文环境中被用于扩散/展开一个值,比如在另一个数组声明内部:
var a = [2,3,4];var b = [ 1, ...a, 5 ];console.log( b ); // [1,2,3,4,5]
在这种用法中,...取代了concat(..),它在这里的行为就像[1].concat( a, [5] )。
另一种...的用法常见于一种实质上相反的操作;与将值散开不同,...将一组值 收集 到一个数组中。
function foo(x, y, ...z) {console.log( x, y, z );}foo( 1, 2, 3, 4, 5 ); // 1 2 [3,4,5]
这个代码段中的...z实质上是在说:“将 剩余的 参数值(如果有的话)收集到一个称为z的数组中。” 因为x被赋值为1,而y被赋值为2,所以剩余的参数值3,4,和5被收集进了z。
当然,如果你没有任何命名参数,...会收集所有的参数值:
function foo(...args) {console.log( args );}foo( 1, 2, 3, 4, 5); // [1,2,3,4,5]
注意: 在foo(..)函数声明中的...args经常因为你向其中收集参数的剩余部分而被称为“剩余参数”。我喜欢使用“收集”这个词,因为它描述了它做什么而不是它包含什么。
这种用法最棒的地方是,它为被废弃了很久的arguments数组 —— 实际上它不是一个真正的数组,而是一个类数组对象 —— 提供了一种非常稳健的替代方案。因为args(无论你叫它什么 —— 许多人喜欢叫它r或者rest)是一个真正的数组,我们可以摆脱许多愚蠢的前ES6技巧,我们曾经通过这些技巧尽全力去使arguments变成我们可以视之为数组的东西。
考虑如下代码:
// 使用新的ES6方式function foo(...args) {// `args`已经是一个真正的数组了// 丢弃`args`中的第一个元素args.shift();// 将`args`的所有内容作为参数值传给`console.log(..)`console.log( ...args );}// 使用老旧的前ES6方式function bar() {// 将`arguments`转换为一个真正的数组var args = Array.prototype.slice.call( arguments );// 在末尾添加一些元素args.push( 4, 5 );// 过滤掉所有奇数args = args.filter( function(v){return v % 2 == 0;} );// 将`args`的所有内容作为参数值传给`foo(..)`foo.apply( null, args );}bar( 0, 1, 2, 3 ); // 2 4
在函数foo(..)声明中的...args收集参数值,而在console.log(..)调用中的...args将它们扩散开。这个例子很好地展示了...操作符平行但相反的用途。
除了在函数声明中...的用法以外,还有另一种...被用于收集值的情况,我们将在本章稍后的“太多,太少,正合适”一节中检视它。
默认参数值
也许在JavaScript中最常见的惯用法之一就是为函数参数设置默认值。我们多年来一直使用的方法应当看起来很熟悉:
function foo(x,y) {x = x || 11;y = y || 31;console.log( x + y );}foo(); // 42foo( 5, 6 ); // 11foo( 5 ); // 36foo( null, 6 ); // 17
当然,如果你曾经用过这种模式,你就会知道它既有用又有点儿危险,例如如果你需要能够为其中一个参数传入一个可能被认为是falsy的值。考虑下面的代码:
foo( 0, 42 ); // 53 <-- 噢,不是42
为什么?因为0是falsy,因此x || 11的结果为11,而不是直接被传入的0。
为了填这个坑,一些人会像这样更加啰嗦地编写检查:
function foo(x,y) {x = (x !== undefined) ? x : 11;y = (y !== undefined) ? y : 31;console.log( x + y );}foo( 0, 42 ); // 42foo( undefined, 6 ); // 17
当然,这意味着除了undefined以外的任何值都可以直接传入。然而,undefined将被假定是这样一种信号,“我没有传入这个值。” 除非你实际需要能够传入undefined,它就工作的很好。
在那样的情况下,你可以通过测试参数值是否没有出现在arguments数组中,来看它是否实际上被省略了,也许是像这样:
function foo(x,y) {x = (0 in arguments) ? x : 11;y = (1 in arguments) ? y : 31;console.log( x + y );}foo( 5 ); // 36foo( 5, undefined ); // NaN
但是在没有能力传入意味着“我省略了这个参数值”的任何种类的值(连undefined也不行)的情况下,你如何才能省略第一个参数值x呢?
foo(,5)很诱人,但它不是合法的语法。foo.apply(null,[,5])看起来应该可以实现这个技巧,但是apply(..)的奇怪之处意味着这组参数值将被视为[undefined,5],显然它没有被省略。
如果你深入调查下去,你将发现你只能通过简单地传入比“期望的”参数值个数少的参数值来省略末尾的参数值,但是你不能省略在参数值列表中间或者开头的参数值。这就是不可能。
这里有一个施用于JavaScript设计的重要原则需要记住:undefined意味着 缺失。也就是,在undefined和 缺失 之间没有区别,至少是就函数参数值而言。
注意: 容易令人糊涂的是,JS中有其他的地方不适用这种特殊的设计原则,比如带有空值槽的数组。更多信息参见本系列的 类型与文法。
带着所有这些认识,现在我们可以检视在ES6中新增的一种有用的好语法,来简化对丢失的参数值进行默认值的赋值。
function foo(x = 11, y = 31) {console.log( x + y );}foo(); // 42foo( 5, 6 ); // 11foo( 0, 42 ); // 42foo( 5 ); // 36foo( 5, undefined ); // 36 <-- `undefined`是缺失foo( 5, null ); // 5 <-- null强制转换为`0`foo( undefined, 6 ); // 17 <-- `undefined`是缺失foo( null, 6 ); // 6 <-- null强制转换为`0`
注意这些结果,和它们如何暗示了与前面的方式的微妙区别和相似之处。
与常见得多的x || 11惯用法相比,在一个函数声明中的x = 11更像x !== undefined ? x : 11,所以在将你的前ES6代码转换为这种ES6默认参数值语法时要多加小心。
注意: 一个剩余/收集参数(参见“扩散/剩余”)不能拥有默认值。所以,虽然function foo(...vals=[1,2,3]) {看起来是一种迷人的能力,但它不是合法的语法。有必要的话你需要继续手动实施那种逻辑。
默认值表达式
函数默认值可以比像31这样的简单值复杂得多;它们可以是任何合法的表达式,甚至是函数调用:
function bar(val) {console.log( "bar called!" );return y + val;}function foo(x = y + 3, z = bar( x )) {console.log( x, z );}var y = 5;foo(); // "bar called"// 8 13foo( 10 ); // "bar called"// 10 15y = 6;foo( undefined, 10 ); // 9 10
如你所见,默认值表达式是被懒惰地求值的,这意味着他们仅在被需要时运行 —— 也就是,当一个参数的参数值被省略或者为undefined。
这是一个微妙的细节,但是在一个函数声明中的正式参数是在它们自己的作用域中的(将它想象为一个仅仅围绕在函数声明的(..)外面的一个作用域气泡),不是在函数体的作用域中。这意味着在一个默认值表达式中的标识符引用会在首先在正式参数的作用域中查找标识符,然后再查找一个外部作用域。更多信息参见本系列的 作用域与闭包。
考虑如下代码:
var w = 1, z = 2;function foo( x = w + 1, y = x + 1, z = z + 1 ) {console.log( x, y, z );}foo(); // ReferenceError
在默认值表达式w + 1中的w在正式参数作用域中查找w,但没有找到,所以外部作用域的w被使用了。接下来,在默认值表达式x + 1中的x在正式参数的作用域中找到了x,而且走运的是x已经被初始化了,所以对y的赋值工作的很好。
然而,z + 1中的z找到了一个在那个时刻还没有被初始化的参数变量z,所以它绝不会试着在外部作用域中寻找z。
正如我们在本章早先的“let声明”一节中提到过的那样,ES6拥有一个TDZ,它会防止一个变量在它还没有被初始化的状态下被访问。因此,z + 1默认值表达式抛出一个TDZReferenceError错误。
虽然对于代码的清晰度来说不见得是一个好主意,一个默认值表达式甚至可以是一个内联的函数表达式调用 —— 通常被称为一个立即被调用的函数表达式(IIFE):
function foo( x =(function(v){ return v + 11; })( 31 )) {console.log( x );}foo(); // 42
一个IIFE(或者任何其他被执行的内联函数表达式)作为默认值表示来说很合适是非常少见的。如果你发现自己试图这么做,那么就退一步再考虑一下!
警告: 如果一个IIFE试图访问标识符x,而且还没有声明自己的x,那么这也将是一个TDZ错误,就像我们刚才讨论的一样。
前一个代码段的默认值表达式是一个IIFE,这是因为它是通过(31)在内联时立即被执行。如果我们去掉这一部分,赋予x的默认值将会仅仅是一个函数的引用,也许像一个默认的回调。可能有一些情况这种模式将十分有用,比如:
function ajax(url, cb = function(){}) {// ..}ajax( "http://some.url.1" );
这种情况下,我们实质上想在没有其他值被指定时,让默认的cb是一个没有操作的空函数。这个函数表达式只是一个函数引用,不是一个调用它自己(在它末尾没有调用的())以达成自己目的的函数。
从JS的早些年开始,就有一个少为人知但是十分有用的奇怪之处可供我们使用:Function.prototype本身就是一个没有操作的空函数。这样,这个声明可以是cb = Function.prototype而省去内联函数表达式的创建。
解构
ES6引入了一个称为 解构 的新语法特性,如果你将它考虑为 结构化赋值 那么它令人困惑的程度可能会小一些。为了理解它的含义,考虑如下代码:
function foo() {return [1,2,3];}var tmp = foo(),a = tmp[0], b = tmp[1], c = tmp[2];console.log( a, b, c ); // 1 2 3
如你所见,我们创建了一个手动赋值:从foo()返回的数组中的值到个别的变量a,b,和c,而且这么做我们就(不幸地)需要tmp变量。
相似地,我们也可以用对象这么做:
function bar() {return {x: 4,y: 5,z: 6};}var tmp = bar(),x = tmp.x, y = tmp.y, z = tmp.z;console.log( x, y, z ); // 4 5 6
属性值tmp.x被赋值给变量x,tmp.y到y和tmp.z到z也一样。
从一个数组中取得索引的值,或从一个对象中取得属性并手动赋值可以被认为是 结构化赋值。ES6为 解构 增加了一种专门的语法,具体地称为 数组解构 和 对象结构。这种语法消灭了前一个代码段中对变量tmp的需要,使它们更加干净。考虑如下代码:
var [ a, b, c ] = foo();var { x: x, y: y, z: z } = bar();console.log( a, b, c ); // 1 2 3console.log( x, y, z ); // 4 5 6
你很可能更加习惯于看到像[a,b,c]这样的东西出现在一个=赋值的右手边的语法,即作为要被赋予的值。
解构对称地翻转了这个模式,所以在=赋值左手边的[a,b,c]被看作是为了将右手边的数组拆解为分离的变量赋值的某种“模式”。
类似地,{ x: x, y: y, z: z }指明了一种“模式”把来自于bar()的对象拆解为分离的变量赋值。
对象属性赋值模式
让我们深入前一个代码段中的{ x: x, .. }语法。如果属性名与你想要声明的变量名一致,你实际上可以缩写这个语法:
var { x, y, z } = bar();console.log( x, y, z ); // 4 5 6
很酷,对吧?
但{ x, .. }是省略了x:部分还是省略了: x部分?当我们使用这种缩写语法时,我们实际上省略了x:部分。这看起来可能不是一个重要的细节,但是一会儿你就会了解它的重要性。
如果你能写缩写形式,那为什么你还要写出更长的形式呢?因为更长的形式事实上允许你将一个属性赋值给一个不同的变量名称,这有时很有用:
var { x: bam, y: baz, z: bap } = bar();console.log( bam, baz, bap ); // 4 5 6console.log( x, y, z ); // ReferenceError
关于这种对象结构形式有一个微妙但超级重要的怪异之处需要理解。为了展示为什么它可能是一个你需要注意的坑,让我们考虑一下普通对象字面量的“模式”是如何被指定的:
var X = 10, Y = 20;var o = { a: X, b: Y };console.log( o.a, o.b ); // 10 20
在{ a: X, b: Y }中,我们知道a是对象属性,而X是被赋值给它的源值。换句话说,它的语义模式是目标: 源,或者更明显地,属性别名: 值。我们能直观地明白这一点,因为它和=赋值是一样的,而它的模式就是目标 = 源。
然而,当你使用对象解构赋值时 —— 也就是,将看起来像是对象字面量的{ .. }语法放在=操作符的左手边 —— 你反转了这个目标: 源的模式。
回想一下:
var { x: bam, y: baz, z: bap } = bar();
这里面对称的模式是源: 目标(或者值: 属性别名)。x: bam意味着属性x是源值而bam是被赋值的目标变量。换句话说,对象字面量是target <-- source,而对象解构赋值是source --> target。看到它是如何反转的了吗?
有另外一种考虑这种语法的方式,可能有助于缓和这种困惑。考虑如下代码:
var aa = 10, bb = 20;var o = { x: aa, y: bb };var { x: AA, y: BB } = o;console.log( AA, BB ); // 10 20
在{ x: aa, y: bb }这一行中,x和y代表对象属性。在{ x: AA, y: BB }这一行,x和y 也 代表对象属性。
还记得刚才我是如何断言{ x, .. }省去了x:部分的吗?在这两行中,如果你在代码段中擦掉x:和y:部分,仅留下aa, bb和AA, BB,它的效果 —— 从概念上讲,实际上不能 —— 将是从aa赋值到AA和从bb赋值到BB。
所以,这种平行性也许有助于解释为什么对于这种ES6特性,语法模式被故意地反转了。
注意: 对于解构赋值来说我更喜欢它的语法是{ AA: x , BB: y },因为那样的话可以在两种用法中一致地使用我们更熟悉的target: source模式。唉,我已经被迫训练自己的大脑去习惯这种反转了,就像一些读者也不得不去做的那样。
不仅是声明
至此,我们一直将解构赋值与var声明(当然,它们也可以使用let和const)一起使用,但是解构是一种一般意义上的赋值操作,不仅是一种声明。
考虑如下代码:
var a, b, c, x, y, z;[a,b,c] = foo();( { x, y, z } = bar() );console.log( a, b, c ); // 1 2 3console.log( x, y, z ); // 4 5 6
变量可以是已经被定义好的,然后解构仅仅负责赋值,正如我们已经看到的那样。
注意: 特别对于对象解构形式来说,当我们省略了var/let/const声明符时,就必须将整个赋值表达式包含在()中,因为如果不这样做的话左手边作为语句第一个元素的{ .. }将被视为一个语句块儿而不是一个对象。
事实上,变量表达式(a,y,等等)不必是一个变量标识符。任何合法的赋值表达式都是允许的。例如:
var o = {};[o.a, o.b, o.c] = foo();( { x: o.x, y: o.y, z: o.z } = bar() );console.log( o.a, o.b, o.c ); // 1 2 3console.log( o.x, o.y, o.z ); // 4 5 6
你甚至可以在解构中使用计算型属性名。考虑如下代码:
var which = "x",o = {};( { [which]: o[which] } = bar() );console.log( o.x ); // 4
[which]:的部分是计算型属性名,它的结果是x —— 将从当前的对象中拆解出来作为赋值的源头的属性。o[which]的部分只是一个普通的对象键引用,作为赋值的目标来说它与o.x是等价的。
你可以使用普通的赋值来创建对象映射/变形,例如:
var o1 = { a: 1, b: 2, c: 3 },o2 = {};( { a: o2.x, b: o2.y, c: o2.z } = o1 );console.log( o2.x, o2.y, o2.z ); // 1 2 3
或者你可以将对象映射进一个数组,例如:
var o1 = { a: 1, b: 2, c: 3 },a2 = [];( { a: a2[0], b: a2[1], c: a2[2] } = o1 );console.log( a2 ); // [1,2,3]
或者从另一个方向:
var a1 = [ 1, 2, 3 ],o2 = {};[ o2.a, o2.b, o2.c ] = a1;console.log( o2.a, o2.b, o2.c ); // 1 2 3
或者你可以将一个数组重排到另一个数组中:
var a1 = [ 1, 2, 3 ],a2 = [];[ a2[2], a2[0], a2[1] ] = a1;console.log( a2 ); // [2,3,1]
你甚至可以不使用临时变量来解决传统的“交换两个变量”的问题:
var x = 10, y = 20;[ y, x ] = [ x, y ];console.log( x, y ); // 20 10
警告: 小心:你不应该将声明和赋值混在一起,除非你想要所有的赋值表达式 也 被视为声明。否则,你会得到一个语法错误。这就是为什么在刚才的例子中我必须将var a2 = []与[ a2[0], .. ] = ..解构赋值分开做。尝试var [ a2[0], .. ] = ..没有任何意义,因为a2[0]不是一个合法的声明标识符;很显然它也不能隐含地创建一个var a2 = []声明来使用。
重复赋值
对象解构形式允许源属性(持有任意值的类型)被罗列多次。例如:
var { a: X, a: Y } = { a: 1 };X; // 1Y; // 1
这意味着你既可以解构一个子对象/数组属性,也可以捕获这个子对象/数组的值本身。考虑如下代码:
var { a: { x: X, x: Y }, a } = { a: { x: 1 } };X; // 1Y; // 1a; // { x: 1 }( { a: X, a: Y, a: [ Z ] } = { a: [ 1 ] } );X.push( 2 );Y[0] = 10;X; // [10,2]Y; // [10,2]Z; // 1
关于解构有一句话要提醒:像我们到目前为止的讨论中做的那样,将所有的解构赋值都罗列在单独一行中的方式可能很诱人。然而,一个好得多的主意是使用恰当的缩进将解构赋值的模式分散在多行中 —— 和你在JSON或对象字面量中做的事非常相似 —— 为了可读性。
// 很难读懂:var { a: { b: [ c, d ], e: { f } }, g } = obj;// 好一些:var {a: {b: [ c, d ],e: { f }},g} = obj;
记住:解构的目的不仅是为了少打些字,更多是为了声明可读性
解构赋值表达式
带有对象或数组解构的赋值表达式的完成值是右手边完整的对象/数组值。考虑如下代码:
var o = { a:1, b:2, c:3 },a, b, c, p;p = { a, b, c } = o;console.log( a, b, c ); // 1 2 3p === o; // true
在前面的代码段中,p被赋值为对象o的引用,而不是a,b,或c的值。数组解构也是一样:
var o = [1,2,3],a, b, c, p;p = [ a, b, c ] = o;console.log( a, b, c ); // 1 2 3p === o; // true
通过将这个对象/数组作为完成值传递下去,你可将解构赋值表达式链接在一起:
var o = { a:1, b:2, c:3 },p = [4,5,6],a, b, c, x, y, z;( {a} = {b,c} = o );[x,y] = [z] = p;console.log( a, b, c ); // 1 2 3console.log( x, y, z ); // 4 5 4
太多,太少,正合适
对于数组解构赋值和对象解构赋值两者来说,你不必分配所有出现的值。例如:
var [,b] = foo();var { x, z } = bar();console.log( b, x, z ); // 2 4 6
从foo()返回的值1和3被丢弃了,从bar()返回的值5也是。
相似地,如果你试着分配比你正在解构/拆解的值要多的值时,它们会如你所想的那样安静地退回到undefined:
var [,,c,d] = foo();var { w, z } = bar();console.log( c, z ); // 3 6console.log( d, w ); // undefined undefined
这种行为平行地遵循早先提到的“undefined意味着缺失”原则。
我们在本章早先检视了...操作符,并看到了它有时可以用于将一个数组值扩散为它的分离值,而有时它可以被用于相反的操作:将一组值收集进一个数组。
除了在函数声明中的收集/剩余用法以外,...可以在解构赋值中实施相同的行为。为了展示这一点,让我们回想一下本章早先的一个代码段:
var a = [2,3,4];var b = [ 1, ...a, 5 ];console.log( b ); // [1,2,3,4,5]
我们在这里看到因为...a出现在数组[ .. ]中值的位置,所以它将a扩散开。如果...a出现一个数组解构的位置,它会实施收集行为:
var a = [2,3,4];var [ b, ...c ] = a;console.log( b, c ); // 2 [3,4]
解构赋值var [ .. ] = a为了将a赋值给在[ .. ]中描述的模式而将它扩散开。第一部分的名称b对应a中的第一个值(2)。然后...c将剩余的值(3和4)收集到一个称为c的数组中。
注意: 我们已经看到...是如何与数组一起工作的,但是对象呢?那不是一个ES6特性,但是参看第八章中关于一种可能的“ES6之后”的特性的讨论,它可以让...扩散或者收集对象。
默认值赋值
两种形式的解构都可以为赋值提供默认值选项,它使用和早先讨论过的默认函数参数值相似的=语法。
考虑如下代码:
var [ a = 3, b = 6, c = 9, d = 12 ] = foo();var { x = 5, y = 10, z = 15, w = 20 } = bar();console.log( a, b, c, d ); // 1 2 3 12console.log( x, y, z, w ); // 4 5 6 20
你可以将默认值赋值与前面讲过的赋值表达式语法组合在一起。例如:
var { x, y, z, w: WW = 20 } = bar();console.log( x, y, z, WW ); // 4 5 6 20
如果你在一个解构中使用一个对象或者数组作为默认值,那么要小心不要把自己(或者读你的代码的其他开发者)搞糊涂了。你可能会创建一些非常难理解的代码:
var x = 200, y = 300, z = 100;var o1 = { x: { y: 42 }, z: { y: z } };( { y: x = { y: y } } = o1 );( { z: y = { y: z } } = o1 );( { x: z = { y: x } } = o1 );
你能从这个代码段中看出x,y和z最终是什么值吗?花点儿时间好好考虑一下,我能想象你的样子。我会终结这个悬念:
console.log( x.y, y.y, z.y ); // 300 100 42
这里的要点是:解构很棒也可以很有用,但是如果使用得不明智,它也是一把可以伤人(某人的大脑)的利剑。
嵌套解构
如果你正在解构的值拥有嵌套的对象或数组,你也可以解构这些嵌套的值:
var a1 = [ 1, [2, 3, 4], 5 ];var o1 = { x: { y: { z: 6 } } };var [ a, [ b, c, d ], e ] = a1;var { x: { y: { z: w } } } = o1;console.log( a, b, c, d, e ); // 1 2 3 4 5console.log( w ); // 6
嵌套的解构可以是一种将对象名称空间扁平化的简单方法。例如:
var App = {model: {User: function(){ .. }}};// 取代:// var User = App.model.User;var { model: { User } } = App;
参数解构
你能在下面的代码段中发现赋值吗?
function foo(x) {console.log( x );}foo( 42 );
其中的赋值有点儿被隐藏的感觉:当foo(42)被执行时42(参数值)被赋值给x(参数)。如果参数/参数值对是一种赋值,那么按常理说它是一个可以被解构的赋值,对吧?当然!
考虑参数的数组解构:
function foo( [ x, y ] ) {console.log( x, y );}foo( [ 1, 2 ] ); // 1 2foo( [ 1 ] ); // 1 undefinedfoo( [] ); // undefined undefined
参数也可以进行对象解构:
function foo( { x, y } ) {console.log( x, y );}foo( { y: 1, x: 2 } ); // 2 1foo( { y: 42 } ); // undefined 42foo( {} ); // undefined undefined
这种技术是命名参数值(一个长期以来被渴求的JS特性!)的一种近似解法:对象上的属性映射到被解构的同名参数上。这也意味着我们免费地(在任何位置)得到了可选参数,如你所见,省去“参数”x可以如我们期望的那样工作。
当然,先前讨论过的所有解构的种类对于参数解构来说都是可用的,包括嵌套解构,默认值,和其他。解构也可以和其他ES6函数参数功能很好地混合在一起,比如默认参数值和剩余/收集参数。
考虑这些快速的示例(当然这没有穷尽所有可能的种类):
function f1([ x=2, y=3, z ]) { .. }function f2([ x, y, ...z], w) { .. }function f3([ x, y, ...z], ...w) { .. }function f4({ x: X, y }) { .. }function f5({ x: X = 10, y = 20 }) { .. }function f6({ x = 10 } = {}, { y } = { y: 10 }) { .. }
为了展示一下,让我们从这个代码段中取一个例子来检视:
function f3([ x, y, ...z], ...w) {console.log( x, y, z, w );}f3( [] ); // undefined undefined [] []f3( [1,2,3,4], 5, 6 ); // 1 2 [3,4] [5,6]
这里使用了两个...操作符,他们都是将值收集到数组中(z和w),虽然...z是从第一个数组参数值的剩余值中收集,而...w是从第一个之后的剩余主参数值中收集的。
解构默认值 + 参数默认值
有一个微妙的地方你应当注意要特别小心 —— 解构默认值与函数参数默认值的行为之间的不同。例如:
function f6({ x = 10 } = {}, { y } = { y: 10 }) {console.log( x, y );}f6(); // 10 10
首先,看起来我们用两种不同的方法为参数x和y都声明了默认值10。然而,这两种不同的方式会在特定的情况下表现出不同的行为,而且这种区别极其微妙。
考虑如下代码:
f6( {}, {} ); // 10 undefined
等等,为什么会这样?十分清楚,如果在第一个参数值的对象中没有一个同名属性被传递,那么命名参数x将默认为10。
但y是undefined是怎么回事儿?值{ y: 10 }是一个作为函数参数默认值的对象,不是结构默认值。因此,它仅在第二个参数根本没有被传递,或者undefined被传递时生效,
在前面的代码段中,我们传递了第二个参数({}),所以默认值{ y: 10 }不被使用,而解构{ y }会针对被传入的空对象值{}发生。
现在,将{ y } = { y: 10 }与{ x = 10 } = {}比较一下。
对于x的使用形式来说,如果第一个函数参数值被省略或者是undefined,会默认地使用空对象{}。然后,不管在第一个参数值的位置上是什么值 —— 要么是默认的{},要么是你传入的 —— 都会被{ x = 10 }解构,它会检查属性x是否被找到,如果没有找到(或者是undefined),默认值10会被设置到命名参数x上。
深呼吸。回过头去把最后几段多读几遍。让我们用代码复习一下:
function f6({ x = 10 } = {}, { y } = { y: 10 }) {console.log( x, y );}f6(); // 10 10f6( undefined, undefined ); // 10 10f6( {}, undefined ); // 10 10f6( {}, {} ); // 10 undefinedf6( undefined, {} ); // 10 undefinedf6( { x: 2 }, { y: 3 } ); // 2 3
一般来说,与参数y的默认行为比起来,参数x的默认行为可能看起来更可取也更合理。因此,理解{ x = 10 } = {}形式与{ y } = { y: 10 }形式为何与如何不同是很重要的。
如果这仍然有点儿模糊,回头再把它读一遍,并亲自把它玩弄一番。未来的你将会感谢你花了时间把这种非常微妙的,晦涩的细节的坑搞明白。
嵌套默认值:解构与重构
虽然一开始可能很难掌握,但是为一个嵌套的对象的属性设置默认值产生了一种有趣的惯用法:将对象解构与一种我称为 重构 的东西一起使用。
考虑在一个嵌套的对象结构中的一组默认值,就像下面这样:
// 摘自:http://es-discourse.com/t/partial-default-arguments/120/7var defaults = {options: {remove: true,enable: false,instance: {}},log: {warn: true,error: true}};
现在,我们假定你有一个称为config的对象,它有一些这其中的值,但也许不全有,而且你想要将所有的默认值设置到这个对象的缺失点上,但不覆盖已经存在的特定设置:
var config = {options: {remove: false,instance: null}};
你当然可以手动这样做,就像你可能曾经做过的那样:
config.options = config.options || {};config.options.remove = (config.options.remove !== undefined) ?config.options.remove : defaults.options.remove;config.options.enable = (config.options.enable !== undefined) ?config.options.enable : defaults.options.enable;...
讨厌。
另一些人可能喜欢用覆盖赋值的方式来完成这个任务。你可能会被ES6的Object.assign(..)工具(见第六章)所吸引,来首先克隆defaults中的属性然后使用从config中克隆的属性覆盖它,像这样:
config = Object.assign( {}, defaults, config );
这看起来好多了,是吧?但是这里有一个重大问题!Object.assign(..)是浅拷贝,这意味着当它拷贝defaults.options时,它仅仅拷贝这个对象的引用,而不是深度克隆这个对象的属性到一个config.options对象。Object.assign(..)需要在你的对象树的每一层中实施才能得到你期望的深度克隆。
注意: 许多JS工具库/框架都为对象的深度克隆提供它们自己的选项,但是那些方式和它们的坑超出了我们在这里的讨论范围。
那么让我们检视一下ES6的带有默认值的对象解构能否帮到我们:
config.options = config.options || {};config.log = config.log || {};({options: {remove: config.options.remove = defaults.options.remove,enable: config.options.enable = defaults.options.enable,instance: config.options.instance = defaults.options.instance} = {},log: {warn: config.log.warn = defaults.log.warn,error: config.log.error = defaults.log.error} = {}} = config);
不像Object.assign(..)的虚假诺言(因为它只是浅拷贝)那么好,但是我想它要比手动的方式强多了。虽然它仍然很不幸地带有冗余和重复。
前面的代码段的方式可以工作,因为我黑进了结构和默认机制来为我做属性的=== undefined检查和赋值的决定。这里的技巧是,我解构了config(看看在代码段末尾的= config),但是我将所有解构出来的值又立即赋值回config,带着config.options.enable赋值引用。
但还是太多了。让我们看看能否做得更好。
下面的技巧在你知道你正在解构的所有属性的名称都是唯一的情况下工作得最好。但即使不是这样的情况你也仍然可以使用它,只是没有那么好 —— 你将不得不分阶段解构,或者创建独一无二的本地变量作为临时的别名。
如果我们将所有的属性完全解构为顶层变量,那么我们就可以立即重构来重组原本的嵌套对象解构。
但是所有那些游荡在外的临时变量将会污染作用域。所以,让我们通过一个普通的{ }包围块儿来使用块儿作用域(参见本章早先的“块儿作用域声明”)。
// 将`defaults`混入`config`{// 解构(使用默认值赋值)let {options: {remove = defaults.options.remove,enable = defaults.options.enable,instance = defaults.options.instance} = {},log: {warn = defaults.log.warn,error = defaults.log.error} = {}} = config;// 重构config = {options: { remove, enable, instance },log: { warn, error }};}
这看起来好多了,是吧?
注意: 你也可以使用箭头IIFE来代替一般的{ }块儿和let声明来达到圈占作用域的目的。你的解构赋值/默认值将位于参数列表中,而你的重构将位于函数体的return语句中。
在重构部分的{ warn, error }语法可能是你初次见到;它称为“简约属性”,我们将在下一节讲解它!
对象字面量扩展
ES6给不起眼儿的{ .. }对象字面量增加了几个重要的便利扩展。
简约属性
你一定很熟悉用这种形式的对象字面量声明:
var x = 2, y = 3,o = {x: x,y: y};
如果到处说x: x总是让你感到繁冗,那么有个好消息。如果你需要定义一个名称和词法标识符一致的属性,你可以将它从x: x缩写为x。考虑如下代码:
var x = 2, y = 3,o = {x,y};
简约方法
本着与我们刚刚检视的简约属性相同的精神,添附在对象字面量属性上的函数也有一种便利简约形式。
以前的方式:
var o = {x: function(){// ..},y: function(){// ..}}
而在ES6中:
var o = {x() {// ..},y() {// ..}}
警告: 虽然x() { .. }看起来只是x: function(){ .. }的缩写,但是简约方法有一种特殊行为,是它们对应的老方式所不具有的;确切地说,是允许super(参见本章稍后的“对象super”)的使用。
Generator(见第四章)也有一种简约方法形式:
var o = {*foo() { .. }};
简约匿名
虽然这种便利缩写十分诱人,但是这其中有一个微妙的坑要小心。为了展示这一点,让我们检视一下如下的前ES6代码,你可能会试着使用简约方法来重构它:
function runSomething(o) {var x = Math.random(),y = Math.random();return o.something( x, y );}runSomething( {something: function something(x,y) {if (x > y) {// 使用相互对调的`x`和`y`来递归地调用return something( y, x );}return y - x;}} );
这段蠢代码只是生成两个随机数,然后用大的减去小的。但这里重要的不是它做的是什么,而是它是如何被定义的。让我把焦点放在对象字面量和函数定义上,就像我们在这里看到的:
runSomething( {something: function something(x,y) {// ..}} );
为什么我们同时说something:和function something?这不是冗余吗?实际上,不是,它们俩被用于不同的目的。属性something让我们能够调用o.something(..),有点儿像它的公有名称。但是第二个something是一个词法名称,使这个函数可以为了递归而从内部引用它自己。
你能看出来为什么return something(y,x)这一行需要名称something来引用这个函数吗?因为这里没有对象的词法名称,要是有的话我们就可以说return o.something(y,x)或者其他类似的东西。
当一个对象字面量的确拥有一个标识符名称时,这其实是一个很常见的做法,比如:
var controller = {makeRequest: function(..){// ..controller.makeRequest(..);}};
这是个好主意吗?也许是,也许不是。你在假设名称controller将总是指向目标对象。但它也很可能不是 —— 函数makeRequest(..)不能控制外部的代码,因此不能强制你的假设一定成立。这可能会回过头来咬到你。
另一些人喜欢使用this定义这样的东西:
var controller = {makeRequest: function(..){// ..this.makeRequest(..);}};
这看起来不错,而且如果你总是用controller.makeRequest(..)来调用方法的话它就应该能工作。但现在你有一个this绑定的坑,如果你做这样的事情的话:
btn.addEventListener( "click", controller.makeRequest, false );
当然,你可以通过传递controller.makeRequest.bind(controller)作为绑定到事件上的处理器引用来解决这个问题。但是这很讨厌 —— 它不是很吸引人。
或者要是你的内部this.makeRequest(..)调用需要从一个嵌套的函数内发起呢?你会有另一个this绑定灾难,人们经常使用var self = this这种用黑科技解决,就像:
var controller = {makeRequest: function(..){var self = this;btn.addEventListener( "click", function(){// ..self.makeRequest(..);}, false );}};
更讨厌。
注意: 更多关于this绑定规则和陷阱的信息,参见本系列的 this与对象原型 的第一到二章。
好了,这些与简约方法有什么关系?回想一下我们的something(..)方法定义:
runSomething( {something: function something(x,y) {// ..}} );
在这里的第二个something提供了一个超级便利的词法标识符,它总是指向函数自己,给了我们一个可用于递归,事件绑定/解除等等的完美引用 —— 不用乱搞this或者使用不可靠的对象引用。
太好了!
那么,现在我们试着将函数引用重构为这种ES6解约方法的形式:
runSomething( {something(x,y) {if (x > y) {return something( y, x );}return y - x;}} );
第一眼看上去不错,除了这个代码将会坏掉。return something(..)调用经不会找到something标识符,所以你会得到一个ReferenceError。噢,但为什么?
上面的ES6代码段将会被翻译为:
runSomething( {something: function(x,y){if (x > y) {return something( y, x );}return y - x;}} );
仔细看。你看出问题了吗?简约方法定义暗指something: function(x,y)。看到我们依靠的第二个something是如何被省略的了吗?换句话说,简约方法暗指匿名函数表达式。
对,讨厌。
注意: 你可能认为在这里=>箭头函数是一个好的解决方案。但是它们也同样不够,因为它们也是匿名函数表达式。我们将在本章稍后的“箭头函数”中讲解它们。
一个部分地补偿了这一点的消息是,我们的简约函数something(x,y)将不会是完全匿名的。参见第七章的“函数名”来了解ES6函数名称的推断规则。这不会在递归中帮到我们,但是它至少在调试时有用处。
那么我们怎样总结简约方法?它们简短又甜蜜,而且很方便。但是你应当仅在你永远不需要将它们用于递归或事件绑定/解除时使用它们。否则,就坚持使用你的老式something: function something(..)方法定义。
你的很多方法都将可能从简约方法定义中受益,这是个非常好的消息!只要小心几处未命名的灾难就好。
ES5 Getter/Setter
技术上讲,ES5定义了getter/setter字面形式,但是看起来它们没有被太多地使用,这主要是由于缺乏转译器来处理这种新的语法(其实,它是ES5中加入的唯一的主要新语法)。所以虽然它不是一个ES6的新特性,我们也将简单地复习一下这种形式,因为它可能会随着ES6的向前发展而变得有用得多。
考虑如下代码:
var o = {__id: 10,get id() { return this.__id++; },set id(v) { this.__id = v; }}o.id; // 10o.id; // 11o.id = 20;o.id; // 20// 而:o.__id; // 21o.__id; // 还是 —— 21!
这些getter和setter字面形式也可以出现在类中;参见第三章。
警告: 可能不太明显,但是setter字面量必须恰好有一个被声明的参数;省略它或罗列其他的参数都是不合法的语法。这个单独的必须参数 可以 使用解构和默认值(例如,set id({ id: v = 0 }) { .. }),但是收集/剩余...是不允许的(set id(...v) { .. })。
计算型属性名
你可能曾经遇到过像下面的代码段那样的情况,你的一个或多个属性名来自于某种表达式,因此你不能将它们放在对象字面量中:
var prefix = "user_";var o = {baz: function(..){ .. }};o[ prefix + "foo" ] = function(..){ .. };o[ prefix + "bar" ] = function(..){ .. };..
ES6为对象字面定义增加了一种语法,它允许你指定一个应当被计算的表达式,其结果就是被赋值属性名。考虑如下代码:
var prefix = "user_";var o = {baz: function(..){ .. },[ prefix + "foo" ]: function(..){ .. },[ prefix + "bar" ]: function(..){ .. }..};
任何合法的表达式都可以出现在位于对象字面定义的属性名位置的[ .. ]内部。
很有可能,计算型属性名最经常与Symbol(我们将在本章稍后的“Symbol”中讲解)一起使用,比如:
var o = {[Symbol.toStringTag]: "really cool thing",..};
Symbol.toStringTag是一个特殊的内建值,我们使用[ .. ]语法求值得到,所以我们可以将值"really cool thing"赋值给这个特殊的属性名。
计算型属性名还可以作为简约方法或简约generator的名称出现:
var o = {["f" + "oo"]() { .. } // 计算型简约方法*["b" + "ar"]() { .. } // 计算型简约generator};
设置[[Prototype]]
我们不会在这里讲解原型的细节,所以关于它的更多信息,参见本系列的 this与对象原型。
有时候在你声明对象字面量的同时给它的[[Prototype]]赋值很有用。下面的代码在一段时期内曾经是许多JS引擎的一种非标准扩展,但是在ES6中得到了标准化:
var o1 = {// ..};var o2 = {__proto__: o1,// ..};
o2是用一个对象字面量声明的,但它也被[[Prototype]]链接到了o1。这里的__proto__属性名还可以是一个字符串"__proto__",但是要注意它 不能 是一个计算型属性名的结果(参见前一节)。
客气点儿说,__proto__是有争议的。在ES6中,它看起来是一个最终被很勉强地标准化了的,几十年前的自主扩展功能。实际上,它属于ES6的“Annex B”,这一部分罗列了JS感觉它仅仅为了兼容性的原因,而不得不标准化的东西。
警告: 虽然我勉强赞同在一个对象字面定义中将__proto__作为一个键,但我绝对不赞同在对象属性形式中使用它,就像o.__proto__。这种形式既是一个getter也是一个setter(同样也是为了兼容性的原因),但绝对存在更好的选择。更多信息参见本系列的 this与对象原型。
对于给一个既存的对象设置[[Prototype]],你可以使用ES6的工具Object.setPrototypeOf(..)。考虑如下代码:
var o1 = {// ..};var o2 = {// ..};Object.setPrototypeOf( o2, o1 );
注意: 我们将在第六章中再次讨论Object。“Object.setPrototypeOf(..)静态函数”提供了关于Object.setPrototypeOf(..)的额外细节。另外参见“Object.assign(..)静态函数”来了解另一种将o2原型关联到o1的形式。
对象super
super通常被认为是仅与类有关。然而,由于JS对象仅有原型而没有类的性质,super是同样有效的,而且在普通对象的简约方法中行为几乎一样。
考虑如下代码:
var o1 = {foo() {console.log( "o1:foo" );}};var o2 = {foo() {super.foo();console.log( "o2:foo" );}};Object.setPrototypeOf( o2, o1 );o2.foo(); // o1:foo// o2:foo
警告: super仅在简约方法中允许使用,而不允许在普通的函数表达式属性中。而且它还仅允许使用super.XXX形式(属性/方法访问),而不是super()形式。
在方法o2.foo()中的super引用被静态地锁定在了o2,而且明确地说是o2的[[Prototype]]。这里的super基本上是Object.getPrototypeOf(o2) —— 显然被解析为o1 —— 这就是他如何找到并调用o1.foo()的。
关于super的完整细节,参见第三章的“类”。
模板字面量
在这一节的最开始,我将不得不呼唤这个ES6特性的极其……误导人的名称,这要看在你的经验中 模板(template) 一词的含义是什么。
许多开发者认为模板是一段可复用的,可重绘的文本,就像大多数模板引擎(Mustache,Handlebars,等等)提供的能力那样。ES6中使用的 模板 一词暗示着相似的东西,就像一种声明可以被重绘的内联模板字面量的方法。然而,这根本不是考虑这个特性的正确方式。
所以,在我们继续之前,我把它重命名为它本应被称呼的名字:插值型字符串字面量(或者略称为 插值型字面量)。
你已经十分清楚地知道了如何使用"或'分隔符来声明字符串字面量,而且你还知道它们不是(像有些语言中拥有的)内容将被解析为插值表达式的 智能字符串。
但是,ES6引入了一种新型的字符串字面量,使用反引号`作为分隔符。这些字符串字面量允许嵌入基本的字符串插值表达式,之后这些表达式自动地被解析和求值。
这是老式的前ES6方式:
var name = "Kyle";var greeting = "Hello " + name + "!";console.log( greeting ); // "Hello Kyle!"console.log( typeof greeting ); // "string"
现在,考虑这种新的ES6方式:
var name = "Kyle";var greeting = `Hello ${name}!`;console.log( greeting ); // "Hello Kyle!"console.log( typeof greeting ); // "string"
如你所见,我们在一系列被翻译为字符串字面量的字符周围使用了`..`,但是${..}形式中的任何表达式都将立即内联地被解析和求值。称呼这样的解析和求值的高大上名词就是 插值(interpolation)(比模板要准确多了)。
被插值的字符串字面量表达式的结果只是一个老式的普通字符串,赋值给变量greeting。
警告: typeof greeting == "string"展示了为什么不将这些实体考虑为特殊的模板值很重要,因为你不能将这种字面量的未求值形式赋值给某些东西并复用它。`..`字符串字面量在某种意义上更像是IIFE,因为它自动内联地被求值。`..`字符串字面量的结果只不过是一个简单的字符串。
插值型字符串字面量的一个真正的好处是他们允许被分割为多行:
var text =`Now is the time for all good mento come to the aid of theircountry!`;console.log( text );// Now is the time for all good men// to come to the aid of their// country!
在插值型字符串字面量中的换行将会被保留在字符串值中。
除非在字面量值中作为明确的转义序列出现,回车字符\r(编码点U+000D)的值或者回车+换行序列\r\n(编码点U+000D和U+000A)的值都会被泛化为一个换行字符\n(编码点U+000A)。但不要担心;这种泛化很少见而且很可能仅会在你将文本拷贝粘贴到JS文件中时才会发生。
插值表达式
在一个插值型字符串字面量中,任何合法的表达式都被允许出现在${..}内部,包括函数调用,内联函数表达式调用,甚至是另一个插值型字符串字面量!
考虑如下代码:
function upper(s) {return s.toUpperCase();}var who = "reader";var text =`A very ${upper( "warm" )} welcometo all of you ${upper( `${who}s` )}!`;console.log( text );// A very WARM welcome// to all of you READERS!
当我们组合变量who与字符串s时, 相对于who + "s",这里的内部插值型字符串字面量`${who}s`更方便一些。有些情况下嵌套的插值型字符串字面量是有用的,但是如果你发现自己做这样的事情太频繁,或者发现你自己嵌套了好几层时,你就要小心一些。
如果确实有这样情况,你的字符串你值生产过程很可能可以从某些抽象中获益。
警告: 作为一个忠告,使用这样的新发现的力量时要非常小心你代码的可读性。就像默认值表达式和解构赋值表达式一样,仅仅因为你 能 做某些事情,并不意味着你 应该 做这些事情。在使用新的ES6技巧时千万不要做过了头,使你的代码比你或者你的其他队友聪明。
表达式作用域
关于作用域的一个快速提醒是它用于解析表达式中的变量时。我早先提到过一个插值型字符串字面量与IIFE有些相像,事实上这也可以考虑为作用域行为的一种解释。
考虑如下代码:
function foo(str) {var name = "foo";console.log( str );}function bar() {var name = "bar";foo( `Hello from ${name}!` );}var name = "global";bar(); // "Hello from bar!"
在函数bar()内部,字符串字面量`..`被表达的那一刻,可供它查找的作用域发现变量的name的值为"bar"。既不是全局的name也不是foo(..)的name。换句话说,一个插值型字符串字面量在它出现的地方是词法作用域的,而不是任何方式的动态作用域。
标签型模板字面量
再次为了合理性而重命名这个特性:标签型字符串字面量。
老实说,这是一个ES6提供的更酷的特性。它可能看起来有点儿奇怪,而且也许一开始看起来一般不那么实用。但一旦你花些时间在它上面,标签型字符串字面量的用处可能会令你惊讶。
例如:
function foo(strings, ...values) {console.log( strings );console.log( values );}var desc = "awesome";foo`Everything is ${desc}!`;// [ "Everything is ", "!"]// [ "awesome" ]
让我们花点儿时间考虑一下前面的代码段中发生了什么。首先,跳出来的最刺眼的东西就是foo`Everything...`;。它看起来不像是任何我们曾经见过的东西。不是吗?
它实质上是一种不需要( .. )的特殊函数调用。标签 —— 在字符串字面量`..`之前的foo部分 —— 是一个应当被调用的函数的值。实际上,它可以是返回函数的任何表达式,甚至是一个返回另一个函数的函数调用,就像:
function bar() {return function foo(strings, ...values) {console.log( strings );console.log( values );}}var desc = "awesome";bar()`Everything is ${desc}!`;// [ "Everything is ", "!"]// [ "awesome" ]
但是当作为一个字符串字面量的标签时,函数foo(..)被传入了什么?
第一个参数值 —— 我们称它为strings —— 是一个所有普通字符串的数组(所有被插值的表达式之间的东西)。我们在strings数组中得到两个值:"Everything is "和"!"。
之后为了我们示例的方便,我们使用...收集/剩余操作符(见本章早先的“扩散/剩余”部分)将所有后续的参数值收集到一个称为values的数组中,虽说你本来当然可以把它们留作参数strings后面单独的命名参数。
被收集进我们的values数组中的参数值,就是在字符串字面量中发现的,已经被求过值的插值表达式的结果。所以在我们的例子中values里唯一的元素显然就是awesome。
你可以将这两个数组考虑为:在values中的值原本是你拼接在stings的值之间的分隔符,而且如果你将所有的东西连接在一起,你就会得到完整的插值字符串值。
一个标签型字符串字面量像是一个在插值表达式被求值之后,但是在最终的字符串被编译之前的处理步骤,允许你在从字面量中产生字符串的过程中进行更多的控制。
一般来说,一个字符串字面量标签函数(在前面的代码段中是foo(..))应当计算一个恰当的字符串值并返回它,所以你可以使用标签型字符串字面量作为一个未打标签的字符串字面量来使用:
function tag(strings, ...values) {return strings.reduce( function(s,v,idx){return s + (idx > 0 ? values[idx-1] : "") + v;}, "" );}var desc = "awesome";var text = tag`Everything is ${desc}!`;console.log( text ); // Everything is awesome!
在这个代码段中,tag(..)是一个直通操作,因为它不实施任何特殊的修改,而只是使用reduce(..)来循环遍历,并像一个未打标签的字符串字面量一样,将strings和values拼接/穿插在一起。
那么实际的用法是什么?有许多高级的用法超出了我们要在这里讨论的范围。但这里有一个格式化美元数字的简单想法(有些像基本的本地化):
function dollabillsyall(strings, ...values) {return strings.reduce( function(s,v,idx){if (idx > 0) {if (typeof values[idx-1] == "number") {// 看,也使用插值性字符串字面量!s += `$${values[idx-1].toFixed( 2 )}`;}else {s += values[idx-1];}}return s + v;}, "" );}var amt1 = 11.99,amt2 = amt1 * 1.08,name = "Kyle";var text = dollabillsyall`Thanks for your purchase, ${name}! Yourproduct cost was ${amt1}, which with taxcomes out to ${amt2}.`console.log( text );// Thanks for your purchase, Kyle! Your// product cost was $11.99, which with tax// comes out to $12.95.
如果在values数组中遇到一个number值,我们就在它前面放一个"$"并用toFixed(2)将它格式化为小数点后两位有效。否则,我们就不碰这个值而让它直通过去。
原始字符串
在前一个代码段中,我们的标签函数接受的第一个参数值称为strings,是一个数组。但是有一点儿额外的数据被包含了进来:所有字符串的原始未处理版本。你可以使用.raw属性访问这些原始字符串值,就像这样:
function showraw(strings, ...values) {console.log( strings );console.log( strings.raw );}showraw`Hello\nWorld`;// [ "Hello// World" ]// [ "Hello\nWorld" ]
原始版本的值保留了原始的转义序列\n(\和n是两个分离的字符),但处理过的版本认为它是一个单独的换行符。但是,早先提到的行终结符泛化操作,是对两个值都实施的。
ES6带来了一个内建函数,它可以用做字符串字面量的标签:String.raw(..)。它简单地直通strings值的原始版本:
console.log( `Hello\nWorld` );// Hello// Worldconsole.log( String.raw`Hello\nWorld` );// Hello\nWorldString.raw`Hello\nWorld`.length;// 12
字符串字面量标签的其他用法包括国际化,本地化,和许多其他的特殊处理。
箭头函数
我们在本章早先接触了函数中this绑定的复杂性,而且在本系列的 this与对象原型 中也以相当的篇幅讲解过。理解普通函数中基于this的编程带来的挫折是很重要的,因为这是ES6的新=>箭头函数的主要动机。
作为与普通函数的比较,我们首先来展示一下箭头函数看起来什么样:
function foo(x,y) {return x + y;}// 对比var foo = (x,y) => x + y;
箭头函数的定义由一个参数列表(零个或多个参数,如果参数不是只有一个,需要有一个( .. )包围这些参数)组成,紧跟着是一个=>符号,然后是一个函数体。
所以,在前面的代码段中,箭头函数只是(x,y) => x + y这一部分,而这个函数的引用刚好被赋值给了变量foo。
函数体仅在含有多于一个表达式,或者由一个非表达式语句组成时才需要用{ .. }括起来。如果仅含有一个表达式,而且你省略了外围的{ .. },那么在这个表达式前面就会有一个隐含的return,就像前面的代码段中展示的那样。
这里是一些其他种类的箭头函数:
var f1 = () => 12;var f2 = x => x * 2;var f3 = (x,y) => {var z = x * 2 + y;y++;x *= 3;return (x + y + z) / 2;};
箭头函数 总是 函数表达式;不存在箭头函数声明。而且很明显它们都是匿名函数表达式 —— 它们没有可以用于递归或者事件绑定/解除的命名引用 —— 但在第七章的“函数名”中将会讲解为了调试的目的而存在的ES6函数名接口规则。
注意: 普通函数参数的所有功能对于箭头函数都是可用的,包括默认值,解构,剩余参数,等等。
箭头函数拥有漂亮,简短的语法,这使得它们在表面上看起来对于编写简洁代码很有吸引力。确实,几乎所有关于ES6的文献(除了这个系列中的书目)看起来都立即将箭头函数仅仅认作“新函数”。
这说明在关于箭头函数的讨论中,几乎所有的例子都是简短的单语句工具,比如那些作为回调传递给各种工具的箭头函数。例如:
var a = [1,2,3,4,5];a = a.map( v => v * 2 );console.log( a ); // [2,4,6,8,10]
在这些情况下,你的内联函数表达式很适合这种在一个单独语句中快速计算并返回结果的模式,对于更繁冗的function关键字和语法来说箭头函数确实看起来是一个很吸人,而且轻量的替代品。
大多数人看着这样简洁的例子都倾向于发出“哦……!啊……!”的感叹,就像我想象中你刚刚做的那样!
然而我要警示你的是,在我看来,使用箭头函数的语法代替普通的,多语句函数,特别是那些可以被自然地表达为函数声明的函数,是某种误用。
回忆本章早前的字符串字面量标签函数dollabillsyall(..) —— 让我们将它改为使用=>语法:
var dollabillsyall = (strings, ...values) =>strings.reduce( (s,v,idx) => {if (idx > 0) {if (typeof values[idx-1] == "number") {// look, also using interpolated// string literals!s += `$${values[idx-1].toFixed( 2 )}`;}else {s += values[idx-1];}}return s + v;}, "" );
在这个例子中,我做的唯一修改是删除了function,return,和一些{ .. },然后插入了=>和一个var。这是对代码可读性的重大改进吗?呵呵。
实际上我会争论,缺少return和外部的{ .. }在某种程度上模糊了这样的事实:reduce(..)调用是函数dollabillsyall(..)中唯一的语句,而且它的结果是这个调用的预期结果。另外,那些受过训练而习惯于在代码中搜索function关键字来寻找作用域边界的眼睛,现在需要搜索=>标志,在密集的代码中这绝对会更加困难。
虽然不是一个硬性规则,但是我要说从=>箭头函数转换得来的可读性,与被转换的函数长度成反比。函数越长,=>能帮的忙越少;函数越短,=>的闪光之处就越多。
我觉得这样做更明智也更合理:在你需要短的内联函数表达式的地方采用=>,但保持你的一般长度的主函数原封不动。
不只是简短的语法,而是this
曾经集中在=>上的大多数注意力都是它通过在你的代码中除去function,return,和{ .. }来节省那些宝贵的击键。
但是至此我们一直忽略了一个重要的细节。我在这一节最开始的时候说过,=>函数与this绑定行为密切相关。事实上,=>箭头函数 主要的设计目的 就是以一种特定的方式改变this的行为,解决在this敏感的编码中的一个痛点。
节省击键是掩人耳目的东西,至多是一个误导人的配角。
让我们重温本章早前的另一个例子:
var controller = {makeRequest: function(..){var self = this;btn.addEventListener( "click", function(){// ..self.makeRequest(..);}, false );}};
我们使用了黑科技var self = this,然后引用了self.makeRequest(..),因为在我们传递给addEventListener(..)的回调函数内部,this绑定将与makeRequest(..)本身中的this绑定不同。换句话说,因为this绑定是动态的,我们通过self变量退回到了可预测的词法作用域。
在这其中我们终于可以看到=>箭头函数主要的设计特性了。在箭头函数内部,this绑定不是动态的,而是词法的。在前一个代码段中,如果我们在回调里使用一个箭头函数,this将会不出所料地成为我们希望它成为的东西。
考虑如下代码:
var controller = {makeRequest: function(..){btn.addEventListener( "click", () => {// ..this.makeRequest(..);}, false );}};
前面代码段的箭头函数中的词法this现在指向的值与外围的makeRequest(..)函数相同。换句话说,=>是var self = this的语法上的替代品。
在var self = this(或者,另一种选择是,.bind(this)调用)通常可以帮忙的情况下,=>箭头函数是一个基于相同原则的很好的替代操作。听起来很棒,是吧?
没那么简单。
如果=>取代var self = this或.bind(this)可以工作,那么猜猜=>用于一个 不需要 var self = this就能工作的this敏感的函数会发生么?你可能会猜到它将会把事情搞砸。没错。
考虑如下代码:
var controller = {makeRequest: (..) => {// ..this.helper(..);},helper: (..) => {// ..}};controller.makeRequest(..);
虽然我们以controller.makeRequest(..)的方式进行了调用,但是this.helper引用失败了,因为这里的this没有像平常那样指向controller。那么它指向哪里?它通过词法继承了外围的作用域中的this。在前面的代码段中,它是全局作用域,this指向了全局作用域。呃。
除了词法的this以外,箭头函数还拥有词法的arguments —— 它们没有自己的arguments数组,而是从它们的上层继承下来 —— 同样还有词法的super和new.target(参见第三章的“类”)。
所以,关于=>在什么情况下合适或不合适,我们现在可以推论出一组更加微妙的规则:
- 如果你有一个简短的,单语句内联函数表达式,它唯一的语句是某个计算后的值的
return语句,并且 这个函数没有在它内部制造一个this引用,并且 没有自引用(递归,事件绑定/解除),并且 你合理地预期这个函数绝不会变得需要this引用或自引用,那么你就可能安全地将它重构为一个=>箭头函数。 - 如果你有一个内部函数表达式,它依赖于外围函数的
var self = this黑科技或者.bind(this)调用来确保正确的this绑定,那么这个内部函数表达式就可能安全地变为一个=>箭头函数。 - 如果你有一个内部函数表达式,它依赖于外围函数的类似于
var args = Array.prototype.slice.call(arguments)这样的东西来制造一个arguments的词法拷贝,那么这个内部函数就可能安全地变为一个=>箭头函数。 - 对于其他的所有东西 —— 普通函数声明,较长的多语句函数表达式,需要词法名称标识符进行自引用(递归等)的函数,和任何其他不符合前述性质的函数 —— 你就可能应当避免
=>函数语法。
底线:=>与this,arguments,和super的词法绑定有关。它们是ES6为了修正一些常见的问题而被有意设计的特性,而不是为了修正bug,怪异的代码,或者错误。
不要相信任何说=>主要是,或者几乎是,为了减少几下击键的炒作。无论你是省下还是浪费了这几下击键,你都应当确切地知道你打入的每个字母是为了做什么。
提示: 如果你有一个函数,由于上述各种清楚的原因而不适合成为一个=>箭头函数,但同时它又被声明为一个对象字面量的一部分,那么回想一下本章早先的“简约方法”,它有简短函数语法的另一种选择。
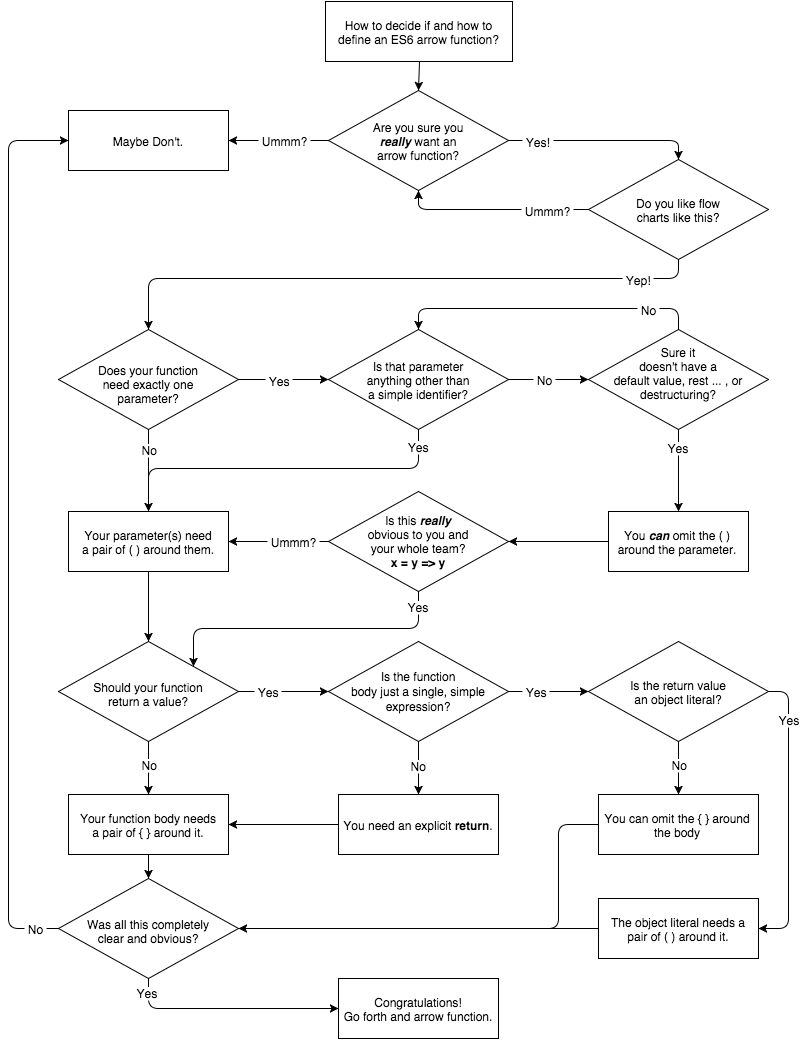
对于如何/为何选用一个箭头函数,如果你喜欢一个可视化的决策图的话:
for..of循环
伴随着我们熟知的JavaScriptfor和for..in循环,ES6增加了一个for..of循环,它循环遍历一组由一个 迭代器(iterator) 产生的值。
你使用for..of循环遍历的值必须是一个 可迭代对象(iterable),或者它必须是一个可以被强制转换/封箱(参见本系列的 类型与文法)为一个可迭代对象的值。一个可迭代对象只不过是一个可以生成迭代器的对象,然后由循环使用这个迭代器。
让我们比较for..of与for..in来展示它们的区别:
var a = ["a","b","c","d","e"];for (var idx in a) {console.log( idx );}// 0 1 2 3 4for (var val of a) {console.log( val );}// "a" "b" "c" "d" "e"
如你所见,for..in循环遍历数组a中的键/索引,而for.of循环遍历a中的值。
这是前面代码段中for..of的前ES6版本:
var a = ["a","b","c","d","e"],k = Object.keys( a );for (var val, i = 0; i < k.length; i++) {val = a[ k[i] ];console.log( val );}// "a" "b" "c" "d" "e"
而这是一个ES6版本的非for..of等价物,它同时展示了手动迭代一个迭代器(见第三章的“迭代器”):
var a = ["a","b","c","d","e"];for (var val, ret, it = a[Symbol.iterator]();(ret = it.next()) && !ret.done;) {val = ret.value;console.log( val );}// "a" "b" "c" "d" "e"
在幕后,for..of循环向可迭代对象要来一个迭代器(使用内建的Symbol.iterator;参见第七章的“通用Symbols”),然后反复调用这个迭代器并将它产生的值赋值给循环迭代的变量。
在JavaScript标准的内建值中,默认为可迭代对象的(或提供可迭代能力的)有:
- 数组
- 字符串
- Generators(见第三章)
- 集合/类型化数组(见第五章)
警告: 普通对象默认是不适用于for..of循环的。因为他们没有默认的迭代器,这是有意为之的,不是一个错误。但是,我们不会进一步探究这其中微妙的原因。在第三章的“迭代器”中,我们将看到如何为我们自己的对象定义迭代器,这允许for..of遍历任何对象来得到我们定义的一组值。
这是如何遍历一个基本类型的字符串中的字符:
for (var c of "hello") {console.log( c );}// "h" "e" "l" "l" "o"
基本类型字符串"hello"被强制转换/封箱为等价的String对象包装器,它是默认就是一个可迭代对象。
在for (XYZ of ABC)..中,XYZ子句既可以是一个赋值表达式也可以是一个声明,这与for和for..in中相同的子句一模一样。所以你可以做这样的事情:
var o = {};for (o.a of [1,2,3]) {console.log( o.a );}// 1 2 3for ({x: o.a} of [ {x: 1}, {x: 2}, {x: 3} ]) {console.log( o.a );}// 1 2 3
与其他的循环一样,使用break,continue,return(如果是在一个函数中),以及抛出异常,for..of循环可以被提前终止。在任何这些情况下,迭代器的return(..)函数(如果存在的话)都会被自动调用,以便让迭代器进行必要的清理工作。
注意: 可迭代对象与迭代器的完整内容参见第三章的“迭代器”。
正则表达式扩展
让我们承认吧:长久以来在JS中正则表达式都没怎么改变过。所以一件很棒的事情是,在ES6中它们终于学会了一些新招数。我们将在这里简要地讲解一下新增的功能,但是正则表达式整体的话题是如此厚重,以至于如果你需要复习一下的话你需要找一些关于它的专门章节/书籍(有许多!)。
Unicode标志
我们将在本章稍后的“Unicode”一节中讲解关于Unicode的更多细节。在此,我们将仅仅简要地看一下ES6+正则表达式的新u标志,它使这个正则表达式的Unicode匹配成为可能。
JavaScript字符串通常被解释为16位字符的序列,它们对应于 基本多文种平面(Basic Multilingual Plane (BMP))中的字符。但是有许多UTF-16字符在这个范围以外,而且字符串可能含有这些多字节字符。
在ES6之前,正则表达式只能基于BMP字符进行匹配,这意味着在匹配时那些扩展字符被看作是两个分离的字符。这通常不理想。
所以,在ES6中,u标志告诉正则表达式使用Unicode(UTF-16)字符的解释方式来处理字符串,这样一来一个扩展的字符将作为一个单独的实体被匹配。
警告: 尽管名字的暗示是这样,但是“UTF-16”并不严格地意味着16位。现代的Unicode使用21位,而且像UTF-8和UTF-16这样的标准大体上是指有多少位用于表示一个字符。
一个例子(直接从ES6语言规范中拿来的): 𝄞 (G大调音乐符号)是Unicode代码点U+1D11E(0x1D11E)。
如果这个字符出现在一个正则表达式范例中(比如/𝄞/),标准的BMP解释方式将认为它是需要被匹配的两个字符(0xD834和0xDD1E)。但是ES6新的Unicode敏感模式意味着/𝄞/u(或者Unicode的转义形式/\u{1D11E}/u)将会把"𝄞"作为一个单独的字符在一个字符串中进行匹配。
你可能想知道为什么这很重要。在非Unicode的BMP模式下,这个正则表达式范例被看作两个分离的字符,但它仍然可以在一个含有"𝄞"字符的字符串中找到匹配,如果你试一下就会看到:
/𝄞/.test( "𝄞-clef" ); // true
重要的是匹配的长度。例如:
/^.-clef/ .test( "𝄞-clef" ); // false/^.-clef/u.test( "𝄞-clef" ); // true
这个范例中的^.-clef说要在普通的"-clef"文本前面只匹配一个单独的字符。在标准的BMP模式下,这个匹配会失败(因为是两个字符),但是在Unicode模式标志位u打开的情况下,这个匹配会成功(一个字符)。
另外一个重要的注意点是,u使像+和*这样的量词实施于作为一个单独字符的整个Unicode代码点,而不仅仅是字符的 低端替代符(也就是符号最右边的一半)。对于出现在字符类中的Unicode字符也是一样,比如/[💩-💫]/u。
注意: 还有许多关于u在正则表达式中行为的细节,对此Mathias Bynens(https://twitter.com/mathias)撰写了大量的作品(https://mathiasbynens.be/notes/es6-unicode-regex)。
粘性标志
另一个加入ES6正则表达式的模式标志是y,它经常被称为“粘性模式(sticky mode)”。粘性 实质上意味着正则表达式在它开始时有一个虚拟的锚点,这个锚点使正则表达式仅以自己的lastIndex属性所指示的位置为起点进行匹配。
为了展示一下,让我们考虑两个正则表达式,第一个没有使用粘性模式而第二个有:
var re1 = /foo/,str = "++foo++";re1.lastIndex; // 0re1.test( str ); // truere1.lastIndex; // 0 —— 没有更新re1.lastIndex = 4;re1.test( str ); // true —— `lastIndex`被忽略了re1.lastIndex; // 4 —— 没有更新
关于这个代码段可以观察到三件事:
test(..)根本不在意lastIndex的值,而总是从输入字符串的开始实施它的匹配。- 因为我们的模式没有输入的起始锚点
^,所以对"foo"的搜索可以在整个字符串上自由向前移动。 lastIndex没有被test(..)更新。
现在,让我们试一下粘性模式的正则表达式:
var re2 = /foo/y, // <-- 注意粘性标志`y`str = "++foo++";re2.lastIndex; // 0re2.test( str ); // false —— 在`0`没有找到“foo”re2.lastIndex; // 0re2.lastIndex = 2;re2.test( str ); // truere2.lastIndex; // 5 —— 在前一次匹配后更新了re2.test( str ); // falsere2.lastIndex; // 0 —— 在前一次匹配失败后重置
于是关于粘性模式我们可以观察到一些新的事实:
test(..)在str中使用lastIndex作为唯一精确的位置来进行匹配。在寻找匹配时不会发生向前的移动 —— 匹配要么出现在lastIndex的位置,要么就不存在。- 如果发生了一个匹配,
test(..)就更新lastIndex使它指向紧随匹配之后的那个字符。如果匹配失败,test(..)就将lastIndex重置为0。
没有使用^固定在输入起点的普通非粘性范例可以自由地在字符串中向前移动来搜索匹配。但是粘性模式制约这个范例仅在lastIndex的位置进行匹配。
正如我在这一节开始时提到过的,另一种考虑的方式是,y暗示着一个虚拟的锚点,它位于正好相对于(也就是制约着匹配的起始位置)lastIndex位置的范例的开头。
警告: 在关于这个话题的以前的文献中,这种行为曾经被声称为y像是在范例中暗示着一个^(输入的起始)锚点。这是不准确的。我们将在稍后的“锚定粘性”中讲解更多细节。
粘性定位
对反复匹配使用y可能看起来是一种奇怪的限制,因为匹配没有向前移动的能力,你不得不手动保证lastIndex恰好位于正确的位置上。
这是一种可能的场景:如果你知道你关心的匹配总是会出现在一个数字(例如,0,10,20,等等)倍数的位置。那么你就可以只构建一个受限的范例来匹配你关心的东西,然后在每次匹配那些固定位置之前手动设置lastIndex。
考虑如下代码:
var re = /f../y,str = "foo far fad";str.match( re ); // ["foo"]re.lastIndex = 10;str.match( re ); // ["far"]re.lastIndex = 20;str.match( re ); // ["fad"]
然而,如果你正在解析一个没有像这样被格式化为固定位置的字符串,在每次匹配之前搞清楚为lastIndex设置什么东西的做法可能会难以维系。
这里有一个微妙之处要考虑。y要求lastIndex位于发生匹配的准确位置。但它不严格要求 你 来手动设置lastIndex。
取而代之的是,你可以用这样的方式构建你的正则表达式:它们在每次主匹配中都捕获你所关心的东西的前后所有内容,直到你想要进行下一次匹配的东西为止。
因为lastIndex将被设置为一个匹配末尾之后的下一个字符,所以如果你已经匹配了到那个位置的所有东西,lastIndex将总是位于下次y范例开始的正确位置。
警告: 如果你不能像这样足够范例化地预知输入字符串的结构,这种技术可能不合适,而且你可能不应使用y。
拥有结构化的字符串输入,可能是y能够在一个字符串上由始至终地进行反复匹配的最实际场景。考虑如下代码:
var re = /\d+\.\s(.*?)(?:\s|$)/ystr = "1. foo 2. bar 3. baz";str.match( re ); // [ "1. foo ", "foo" ]re.lastIndex; // 7 —— 正确位置!str.match( re ); // [ "2. bar ", "bar" ]re.lastIndex; // 14 —— 正确位置!str.match( re ); // ["3. baz", "baz"]
这能够工作是因为我事先知道输入字符串的结构:总是有一个像"1. "这样的数字的前缀出现在期望的匹配("foo",等等)之前,而且它后面要么是一个空格,要么就是字符串的末尾($锚点)。所以我构建的正则表达式在每次主匹配中捕获了所有这一切,然后我使用一个匹配分组( )使我真正关心的东西被方便地分离出来。
在第一次匹配("1. foo ")之后,lastIndex是7,它已经是开始下一次匹配"2. bar "所需的位置了,如此类推。
如果你要使用粘性模式y进行反复匹配,那么你就可能想要像我们刚刚展示的那样寻找一个机会自动地定位lastIndex。
粘性对比全局
一些读者可能意识到,你可以使用全局匹配标志位g和exec(..)方法来模拟某些像lastIndex相对匹配的东西,就像这样:
var re = /o+./g, // <-- 看,`g`!str = "foot book more";re.exec( str ); // ["oot"]re.lastIndex; // 4re.exec( str ); // ["ook"]re.lastIndex; // 9re.exec( str ); // ["or"]re.lastIndex; // 13re.exec( str ); // null —— 没有更多的匹配了!re.lastIndex; // 0 —— 现在重新开始!
虽然使用exec(..)的g范例确实从lastIndex的当前值开始它们的匹配,而且也在每次匹配(或失败)之后更新lastIndex,但这与y的行为不是相同的东西。
注意前面代码段中被第二个exec(..)调用匹配并找到的"ook",被定位在位置6,即便在这个时候lastIndex是4(前一次匹配的末尾)。为什么?因为正如我们前面讲过的,非粘性匹配可以在它们的匹配过程中自由地向前移动。一个粘性模式表达式在这里将会失败,因为它不允许向前移动。
除了也许不被期望的向前移动的匹配行为以外,使用g代替y的另一个缺点是,g改变了一些匹配方法的行为,比如str.match(re)。
考虑如下代码:
var re = /o+./g, // <-- 看,`g`!str = "foot book more";str.match( re ); // ["oot","ook","or"]
看到所有的匹配是如何一次性地被返回的吗?有时这没问题,但有时这不是你想要的。
与test(..)和match(..)这样的工具一起使用,粘性标志位y将给你一次一个的推进式的匹配。只要保证每次匹配时lastIndex总是在正确的位置上就行!
锚定粘性
正如我们早先被警告过的,将粘性模式认为是暗含着一个以^开头的范例是不准确的。在正则表达式中锚点^拥有独特的含义,它 没有 被粘性模式改变。^总是 一个指向输入起点的锚点,而且 不 以任何方式相对于lastIndex。
在这个问题上,除了糟糕/不准确的文档,一个在Firefox中进行的老旧的前ES6粘性模式实验不幸地加深了这种困惑,它确实 曾经 使^相对于lastIndex,所以这种行为曾经存在了许多年。
ES6选择不这么做。^在一个范例中绝对且唯一地意味着输入的起点。
这样的后果是,一个像/^foo/y这样的范例将总是仅在一个字符串的开头找到"foo"匹配,如果它被允许在那里匹配的话。如果lastIndex不是0,匹配就会失败。考虑如下代码:
var re = /^foo/y,str = "foo";re.test( str ); // truere.test( str ); // falsere.lastIndex; // 0 —— 失败之后被重置re.lastIndex = 1;re.test( str ); // false —— 由于定位而失败re.lastIndex; // 0 —— 失败之后被重置
底线:y加^加lastIndex > 0是一种不兼容的组合,它将总是导致失败的匹配。
注意: 虽然y不会以任何方式改变^的含义,但是多行模式m会,这样^就意味着输入的起点 或者 一个换行之后的文本的起点。所以,如果你在一个范例中组合使用y和m,你会在一个字符串中发现多个开始于^的匹配。但是要记住:因为它的粘性y,将不得不在后续的每次匹配时确保lastIndex被置于正确的换行的位置(可能是通过匹配到行的末尾),否者后续的匹配将不会执行。
正则表达式flags
在ES6之前,如果你想要检查一个正则表达式来看看它被施用了什么标志位,你需要将它们 —— 讽刺的是,可能是使用另一个正则表达式 —— 从source属性的内容中解析出来,就像这样:
var re = /foo/ig;re.toString(); // "/foo/ig"var flags = re.toString().match( /\/([gim]*)$/ )[1];flags; // "ig"
在ES6中,你现在可以直接得到这些值,使用新的flags属性:
var re = /foo/ig;re.flags; // "gi"
虽然是个细小的地方,但是ES6规范要求表达式的标志位以"gimuy"的顺序罗列,无论原本的范例中是以什么顺序指定的。这就是出现/ig和"gi"的区别的原因。
是的,标志位被指定和罗列的顺序无所谓。
ES6的另一个调整是,如果你向构造器RegExp(..)传递一个既存的正则表达式,它现在是flags敏感的:
var re1 = /foo*/y;re1.source; // "foo*"re1.flags; // "y"var re2 = new RegExp( re1 );re2.source; // "foo*"re2.flags; // "y"var re3 = new RegExp( re1, "ig" );re3.source; // "foo*"re3.flags; // "gi"
在ES6之前,构造re3将抛出一个错误,但是在ES6中你可以在复制时覆盖标志位。
数字字面量扩展
在ES5之前,数字字面量看起来就像下面的东西 —— 八进制形式没有被官方指定,唯一被允许的是各种浏览器已经实质上达成一致的一种扩展:
var dec = 42,oct = 052,hex = 0x2a;
注意: 虽然你用不同的进制来指定一个数字,但是数字的数学值才是被存储的东西,而且默认的输出解释方式总是10进制的。前面代码段中的三个变量都在它们当中存储了值42。
为了进一步说明052是一种非标准形式扩展,考虑如下代码:
Number( "42" ); // 42Number( "052" ); // 52Number( "0x2a" ); // 42
ES5继续允许这种浏览器扩展的八进制形式(包括这样的不一致性),除了在strict模式下,八进制字面量(052)是不允许的。做出这种限制的主要原因是,许多开发者似乎习惯于下意识地为了将代码对齐而在十进制的数字前面前缀0,然后遭遇他们完全改变了数字的值的意外!
ES6延续了除十进制数字之外的数字字面量可以被表示的遗留的改变/种类。现在有了一种官方的八进制形式,一种改进了的十六进制形式,和一种全新的二进制形式。由于Web兼容性的原因,在非strict模式下老式的八进制形式052将继续是合法的,但其实应当永远不再被使用了。
这些是新的ES6数字字面形式:
var dec = 42,oct = 0o52, // or `0O52` :(hex = 0x2a, // or `0X2a` :/bin = 0b101010; // or `0B101010` :/
唯一允许的小数形式是十进制的。八进制,十六进制,和二进制都是整数形式。
而且所有这些形式的字符串表达形式都是可以被强制转换/变换为它们的数字等价物的:
Number( "42" ); // 42Number( "0o52" ); // 42Number( "0x2a" ); // 42Number( "0b101010" ); // 42
虽然严格来说不是ES6新增的,但一个鲜为人知的事实是你其实可以做反方向的转换(好吧,某种意义上的):
var a = 42;a.toString(); // "42" —— 也可使用`a.toString( 10 )`a.toString( 8 ); // "52"a.toString( 16 ); // "2a"a.toString( 2 ); // "101010"
事实上,以这种方你可以用从2到36的任何进制表达一个数字,虽然你会使用标准进制 —— 2,8,10,和16 ——之外的情况非常少见。
Unicode
我只能说这一节不是一个穷尽了“关于Unicode你想知道的一切”的资料。我想讲解的是,你需要知道在ES6中对Unicode改变了什么,但是我们不会比这深入太多。Mathias Bynens (http://twitter.com/mathias) 大量且出色地撰写/讲解了关于JS和Unicode (参见 https://mathiasbynens.be/notes/javascript-unicode 和 http://fluentconf.com/javascript-html-2015/public/content/2015/02/18-javascript-loves-unicode)。
从0x0000到0xFFFF范围内的Unicode字符包含了所有的标准印刷字符(以各种语言),它们都是你可能看到过和互动过的。这组字符被称为 基本多文种平面(Basic Multilingual Plane (BMP))。BMP甚至包含像这个酷雪人一样的有趣字符: ☃ (U+2603)。
在这个BMP集合之外还有许多扩展的Unicode字符,它们的范围一直到0x10FFFF。这些符号经常被称为 星形(astral) 符号,这正是BMP之外的字符的16组 平面 (也就是,分层/分组)的名称。星形符号的例子包括𝄞 (U+1D11E)和💩 (U+1F4A9)。
在ES6之前,JavaScript字符串可以使用Unicode转义来指定Unicode字符,例如:
var snowman = "\u2603";console.log( snowman ); // "☃"
然而,\uXXXXUnicode转义仅支持四个十六进制字符,所以用这种方式表示你只能表示BMP集合中的字符。要在ES6以前使用Unicode转义表示一个星形字符,你需要使用一个 代理对(surrogate pair) —— 基本上是两个经特殊计算的Unicode转义字符放在一起,被JS解释为一个单独星形字符:
var gclef = "\uD834\uDD1E";console.log( gclef ); // "𝄞"
在ES6中,我们现在有了一种Unicode转义的新形式(在字符串和正则表达式中),称为Unicode 代码点转义:
var gclef = "\u{1D11E}";console.log( gclef ); // "𝄞"
如你所见,它的区别是出现在转义序列中的{ },它允许转义序列中包含任意数量的十六进制字符。因为你只需要六个就可以表示在Unicode中可能的最高代码点(也就是,0x10FFFF),所以这是足够的。
Unicode敏感的字符串操作
在默认情况下,JavaScript字符串操作和方法对字符串值中的星形符号是不敏感的。所以,它们独立地处理每个BMP字符,即便是可以组成一个单独字符的两半代理。考虑如下代码:
var snowman = "☃";snowman.length; // 1var gclef = "𝄞";gclef.length; // 2
那么,我们如何才能正确地计算这样的字符串的长度呢?在这种场景下,下面的技巧可以工作:
var gclef = "𝄞";[...gclef].length; // 1Array.from( gclef ).length; // 1
回想一下本章早先的“for..of循环”一节,ES6字符串拥有内建的迭代器。这个迭代器恰好是Unicode敏感的,这意味着它将自动地把一个星形符号作为一个单独的值输出。我们在一个数组字面量上使用扩散操作符...,利用它创建了一个字符串符号的数组。然后我们只需检查这个结果数组的长度。ES6的Array.from(..)基本上与[...XYZ]做的事情相同,不过我们将在第六章中讲解这个工具的细节。
警告: 应当注意的是,相对地讲,与理论上经过优化的原生工具/属性将做的事情比起来,仅仅为了得到一个字符串的长度就构建并耗尽一个迭代器在性能上的代价是高昂的。
不幸的是,完整的答案并不简单或直接。除了代理对(字符串迭代器可以搞定的),一些特殊的Unicode代码点有其他特殊的行为,解释起来非常困难。例如,有一组代码点可以修改前一个相邻的字符,称为 组合变音符号(Combining Diacritical Marks)
考虑这两个数组的输出:
console.log( s1 ); // "é"console.log( s2 ); // "é"
它们看起来一样,但它们不是!这是我们如何创建s1和s2的:
var s1 = "\xE9",s2 = "e\u0301";
你可能猜到了,我们前面的length技巧对s2不管用:
[...s1].length; // 1[...s2].length; // 2
那么我们能做什么?在这种情况下,我们可以使用ES6的String#normalize(..)工具,在查询这个值的长度前对它实施一个 Unicode正规化操作:
var s1 = "\xE9",s2 = "e\u0301";s1.normalize().length; // 1s2.normalize().length; // 1s1 === s2; // falses1 === s2.normalize(); // true
实质上,normalize(..)接受一个"e\u0301"这样的序列,并把它正规化为\xE9。正规化甚至可以组合多个相邻的组合符号,如果存在适合他们组合的Unicode字符的话:
var s1 = "o\u0302\u0300",s2 = s1.normalize(),s3 = "ồ";s1.length; // 3s2.length; // 1s3.length; // 1s2 === s3; // true
不幸的是,这里的正规化也不完美。如果你有多个组合符号在修改一个字符,你可能不会得到你所期望的长度计数,因为一个被独立定义的,可以表示所有这些符号组合的正规化字符可能不存在。例如:
var s1 = "e\u0301\u0330";console.log( s1 ); // "ḛ́"s1.normalize().length; // 2
你越深入这个兔子洞,你就越能理解要得到一个“长度”的精确定义是很困难的。我们在视觉上看到的作为一个单独字符绘制的东西 —— 更精确地说,它称为一个 字形 —— 在程序处理的意义上不总是严格地关联到一个单独的“字符”上。
提示: 如果你就是想看看这个兔子洞有多深,看看“字形群集边界(Grapheme Cluster Boundaries)”算法(http://www.Unicode.org/reports/tr29/#Grapheme_Cluster_Boundaries)。
字符定位
与长度的复杂性相似,“在位置2上的字符是什么?”,这么问的意思究竟是什么?前ES6的原生答案来自charAt(..),它不会遵守一个星形字符的原子性,也不会考虑组合符号。
考虑如下代码:
var s1 = "abc\u0301d",s2 = "ab\u0107d",s3 = "ab\u{1d49e}d";console.log( s1 ); // "abćd"console.log( s2 ); // "abćd"console.log( s3 ); // "ab𝒞d"s1.charAt( 2 ); // "c"s2.charAt( 2 ); // "ć"s3.charAt( 2 ); // "" <-- 不可打印的代理字符s3.charAt( 3 ); // "" <-- 不可打印的代理字符
那么,ES6会给我们Unicode敏感版本的charAt(..)吗?不幸的是,不。在本书写作时,在后ES6的考虑之中有一个这样的工具的提案。
但是使用我们在前一节探索的东西(当然也带着它的限制!),我们可以黑一个ES6的答案:
var s1 = "abc\u0301d",s2 = "ab\u0107d",s3 = "ab\u{1d49e}d";[...s1.normalize()][2]; // "ć"[...s2.normalize()][2]; // "ć"[...s3.normalize()][2]; // "𝒞"
警告: 提醒一个早先的警告:在每次你想得到一个单独的字符时构建并耗尽一个迭代器……在性能上不是很理想。对此,希望我们很快能在后ES6时代得到一个内建的,优化过的工具。
那么charCodeAt(..)工具的Unicode敏感版本呢?ES6给了我们codePointAt(..):
var s1 = "abc\u0301d",s2 = "ab\u0107d",s3 = "ab\u{1d49e}d";s1.normalize().codePointAt( 2 ).toString( 16 );// "107"s2.normalize().codePointAt( 2 ).toString( 16 );// "107"s3.normalize().codePointAt( 2 ).toString( 16 );// "1d49e"
那么从另一个方向呢?String.fromCharCode(..)的Unicode敏感版本是ES6的String.fromCodePoint(..):
String.fromCodePoint( 0x107 ); // "ć"String.fromCodePoint( 0x1d49e ); // "𝒞"
那么等一下,我们能组合String.fromCodePoint(..)与codePointAt(..)来得到一个刚才的Unicode敏感charAt(..)的更好版本吗?是的!
var s1 = "abc\u0301d",s2 = "ab\u0107d",s3 = "ab\u{1d49e}d";String.fromCodePoint( s1.normalize().codePointAt( 2 ) );// "ć"String.fromCodePoint( s2.normalize().codePointAt( 2 ) );// "ć"String.fromCodePoint( s3.normalize().codePointAt( 2 ) );// "𝒞"
还有好几个字符串方法我们没有在这里讲解,包括toUpperCase(),toLowerCase(),substring(..),indexOf(..),slice(..),以及其他十几个。它们中没有任何一个为了完全支持Unicode而被改变或增强过,所以在处理含有星形符号的字符串是,你应当非常小心 —— 可能干脆回避它们!
还有几个字符串方法为了它们的行为而使用正则表达式,比如replace(..)和match(..)。值得庆幸的是,ES6为正则表达式带来了Unicode支持,正如我们在本章早前的“Unicode标志”中讲解过的那样。
好了,就是这些!有了我们刚刚讲过的各种附加功能,JavaScript的Unicode字符串支持要比前ES6时代好太多了(虽然还不完美)。
Unicode标识符名称
Unicode还可以被用于标识符名称(变量,属性,等等)。在ES6之前,你可以通过Unicode转义这么做,比如:
var \u03A9 = 42;// 等同于:var Ω = 42;
在ES6中,你还可以使用前面讲过的代码点转义语法:
var \u{2B400} = 42;// 等同于:var 𫐀 = 42;
关于究竟哪些Unicode字符被允许使用,有一组复杂的规则。另外,有些字符只要不是标识符名称的第一个字符就允许使用。
注意: 关于所有这些细节,Mathias Bynens写了一篇了不起的文章 (https://mathiasbynens.be/notes/javascript-identifiers-es6)。
很少有理由,或者是为了学术上的目的,才会在标识符名称中使用这样不寻常的字符。你通常不会因为依靠这些深奥的功能编写代码而感到舒服。
Symbol
在ES6中,长久以来首次,有一个新的基本类型被加入到了JavaScript:symbol。但是,与其他的基本类型不同,symbol没有字面形式。
这是你如何创建一个symbol:
var sym = Symbol( "some optional description" );typeof sym; // "symbol"
一些要注意的事情是:
- 你不能也不应该将
new与Symbol(..)一起使用。它不是一个构造器,你也不是在产生一个对象。 - 被传入
Symbol(..)的参数是可选的。如果传入的话,它应当是一个字符串,为symbol的目的给出一个友好的描述。 typeof的输出是一个新的值("symbol"),这是识别一个symbol的主要方法。
如果描述被提供的话,它仅仅用于symbol的字符串化表示:
sym.toString(); // "Symbol(some optional description)"
与基本字符串值如何不是String的实例的原理很相似,symbol也不是Symbol的实例。如果,由于某些原因,你想要为一个symbol值构建一个封箱的包装器对像,你可以做如下的事情:
sym instanceof Symbol; // falsevar symObj = Object( sym );symObj instanceof Symbol; // truesymObj.valueOf() === sym; // true
注意: 在这个代码段中的symObj和sym是可以互换使用的;两种形式可以在symbol被用到的地方使用。没有太多的理由要使用封箱的包装对象形式(symObj),而不用基本类型形式(sym)。和其他基本类型的建议相似,使用sym而非symObj可能是最好的。
一个symbol本身的内部值 —— 称为它的name —— 被隐藏在代码之外而不能取得。你可以认为这个symbol的值是一个自动生成的,(在你的应用程序中)独一无二的字符串值。
但如果这个值是隐藏且不可取得的,那么拥有一个symbol还有什么意义?
一个symbol的主要意义是创建一个不会和其他任何值冲突的类字符串值。所以,举例来说,可以考虑将一个symbol用做表示一个事件的名称的值:
const EVT_LOGIN = Symbol( "event.login" );
然后你可以在一个使用像"event.login"这样的一般字符串字面量的地方使用EVT_LOGIN:
evthub.listen( EVT_LOGIN, function(data){// ..} );
其中的好处是,EVT_LOGIN持有一个不能被其他任何值所(有意或无意地)重复的值,所以在哪个事件被分发或处理的问题上不可能存在任何含糊。
注意: 在前面的代码段的幕后,几乎可以肯定地认为evthub工具使用了EVT_LOGIN参数值的symbol值作为某个跟踪事件处理器的内部对象的属性/键。如果evthub需要将symbol值作为一个真实的字符串使用,那么它将需要使用String(..)或者toString(..)进行明确强制转换,因为symbol的隐含字符串强制转换是不允许的。
你可能会将一个symbol直接用做一个对象中的属性名/键,如此作为一个你想将之用于隐藏或元属性的特殊属性。重要的是,要知道虽然你试图这样对待它,但是它 实际上 并不是隐藏或不可接触的属性。
考虑这个实现了 单例 模式行为的模块 —— 也就是,它仅允许自己被创建一次:
const INSTANCE = Symbol( "instance" );function HappyFace() {if (HappyFace[INSTANCE]) return HappyFace[INSTANCE];function smile() { .. }return HappyFace[INSTANCE] = {smile: smile};}var me = HappyFace(),you = HappyFace();me === you; // true
这里的symbol值INSTANCE是一个被静态地存储在HappyFace()函数对象上的特殊的,几乎是隐藏的,类元属性。
替代性地,它本可以是一个像__instance这样的普通属性,而且其行为将会是一模一样的。symbol的使用仅仅增强了程序元编程的风格,将这个INSTANCE属性与其他普通的属性间保持隔离。
Symbol注册表
在前面几个例子中使用symbol的一个微小的缺点是,变量EVT_LOGIN和INSTANCE不得不存储在外部作用域中(甚至也许是全局作用域),或者用某种方法存储在一个可用的公共位置,这样代码所有需要使用这些symbol的部分都可以访问它们。
为了辅助组织访问这些symbol的代码,你可以使用 全局symbol注册表 来创建symbol。例如:
const EVT_LOGIN = Symbol.for( "event.login" );console.log( EVT_LOGIN ); // Symbol(event.login)
和:
function HappyFace() {const INSTANCE = Symbol.for( "instance" );if (HappyFace[INSTANCE]) return HappyFace[INSTANCE];// ..return HappyFace[INSTANCE] = { .. };}
Symbol.for(..)查询全局symbol注册表来查看一个symbol是否已经使用被提供的说明文本存储过了,如果有就返回它。如果没有,就创建一个并返回。换句话说,全局symbol注册表通过描述文本将symbol值看作它们本身的单例。
但这也意味着只要使用匹配的描述名,你的应用程序的任何部分都可以使用Symbol.for(..)从注册表中取得symbol。
讽刺的是,基本上symbol的本意是在你的应用程序中取代 魔法字符串 的使用(被赋予了特殊意义的随意的字符串值)。但是你正是在全局symbol注册表中使用 魔法 描述字符串值来唯一识别/定位它们的!
为了避免意外的冲突,你可能想使你的symbol描述十分独特。这么做的一个简单的方法是在它们之中包含前缀/环境/名称空间的信息。
例如,考虑一个像下面这样的工具:
function extractValues(str) {var key = Symbol.for( "extractValues.parse" ),re = extractValues[key] ||/[^=&]+?=([^&]+?)(?=&|$)/g,values = [], match;while (match = re.exec( str )) {values.push( match[1] );}return values;}
我们使用魔法字符串值"extractValues.parse",因为在注册表中的其他任何symbol都不太可能与这个描述相冲突。
如果这个工具的一个用户想要覆盖这个解析用的正则表达式,他们也可以使用symbol注册表:
extractValues[Symbol.for( "extractValues.parse" )] =/..some pattern../g;extractValues( "..some string.." );
除了symbol注册表在全局地存储这些值上提供的协助以外,我们在这里看到的一切其实都可以通过将魔法字符串"extractValues.parse"作为一个键,而不是一个symbol,来做到。这其中在元编程的层次上的改进要多于在函数层次上的改进。
你可能偶然会使用一个已经被存储在注册表中的symbol值来查询它底层存储了什么描述文本(键)。例如,因为你无法传递symbol值本身,你可能需要通知你的应用程序的另一个部分如何在注册表中定位一个symbol。
你可以使用Symbol.keyFor(..)取得一个被注册的symbol描述文本(键):
var s = Symbol.for( "something cool" );var desc = Symbol.keyFor( s );console.log( desc ); // "something cool"// 再次从注册表取得symbolvar s2 = Symbol.for( desc );s2 === s; // true
Symbols作为对象属性
如果一个symbol被用作一个对象的属性/键,它会被以一种特殊的方式存储,以至这个属性不会出现在这个对象属性的普通枚举中:
var o = {foo: 42,[ Symbol( "bar" ) ]: "hello world",baz: true};Object.getOwnPropertyNames( o ); // [ "foo","baz" ]
要取得对象的symbol属性:
Object.getOwnPropertySymbols( o ); // [ Symbol(bar) ]
这表明一个属性symbol实际上不是隐藏的或不可访问的,因为你总是可以在Object.getOwnPropertySymbols(..)的列表中看到它。
内建Symbols
ES6带来了好几种预定义的内建symbol,它们暴露了在JavaScript对象值上的各种元行为。然而,正如人们所预料的那样,这些symbol 没有 没被注册到全局symbol注册表中。
取而代之的是,它们作为属性被存储到了Symbol函数对象中。例如,在本章早先的“for..of”一节中,我们介绍了值Symbol.iterator:
var a = [1,2,3];a[Symbol.iterator]; // native function
语言规范使用@@前缀注释指代内建的symbol,最常见的几个是:@@iterator,@@toStringTag,@@toPrimitive。还定义了几个其他的symbol,虽然他们可能不那么频繁地被使用。
注意: 关于这些内建symbol如何被用于元编程的详细信息,参见第七章的“通用Symbol”。
复习
ES6给JavaScript增加了一堆新的语法形式,有好多东西要学!
这些东西中的大多数都是为了缓解常见编程惯用法中的痛点而设计的,比如为函数参数设置默认值和将“剩余”的参数收集到一个数组中。解构是一个强大的工具,用来更简约地表达从数组或嵌套对象的赋值。
虽然像箭头函数=>这样的特性看起来也都是关于更简短更好看的语法,但是它们实际上拥有非常特殊的行为,你应当在恰当的情况下有意地使用它们。
扩展的Unicode支持,新的正则表达式技巧,和新的symbol基本类型充实了ES6语法的发展演变。
你不懂JS(系列丛书)-网页版目录
上一篇 ●【你不懂JS:ES6与未来】第一章:ES?现在与未来
下一篇 ● 【你不懂JS:ES6与未来】第三章:组织
写于 2018年05月26日3748
如非特别注明,文章皆为原创。
转载请注明出处: https://www.liayal.com/article/5b08f2b2912ad10f8b2d13a0
记小栈小程序上线啦~搜索【记小栈】或【点击扫码】体验
{kind=link}
~ 评论还没有,沙发可以有 O(∩_∩)O~